The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
Collaborative robots or cobots are being adopted in large fulfillment centers to streamline logistics with the intent to improve efficiency right from the stage of procurement to last-mile delivery.
As the global collaborative robot market is forecasted to grow at a Compound Annual Growth Rate (CAGR) of 60% by 2030 [3], cobots are paving the way for collaborative, safe and productive warehouse automation. They are equipped with high degrees of autonomy, efficient navigation, and unrivaled flexible robotic manipulation. These robots can be made to work in conjunction with employees processing bulk orders with zero error in the shortest amount of time.
Next Gen AMRs (Autonomous Mobile Robots) – Mobile Cobots
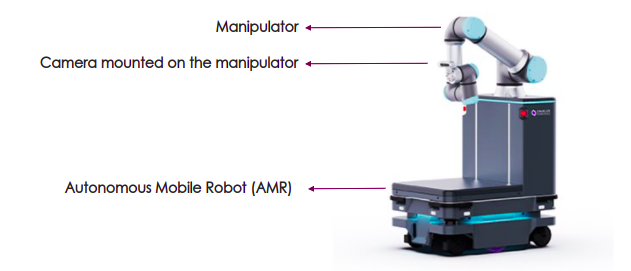
Fig 1: Brief representation of a mobile cobot [4] with highlighted vital components
Along with autonomy, navigation, and manipulation capabilities, it is becoming increasingly important to build Computer Vision capability in cobots. Vision helps cobots detect and locate objects, scan QR codes / bar codes and recognize patterns. In a traditional system, objects and obstacles should be presented to a cobot in a structured way. But with computer vision built into cobots, this is no longer necessary. This means the same cobots can handle several types of tasks – a cobot can be assigned to a particular set of tasks in the morning and a separate set in the afternoon. This provides a great degree of flexibility in operating cobots in warehouses and retail fulfilment centers.
Computer Vision for Cobots
Retail fulfilment centers deal with two variations of object picking application.
Pick – Picking an object from the shelf and placing it in a bin
Environmental conditions play a paramount role in the object pick task. The key factors which highly impact the vision module of the picking task are lighting variations on the shelf, width, and depth of the shelf stack area.
Stow – Picking an object from the bin and stowing the same in the desired shelf.
The sheer unstructured environment (where positions of other objects keep on changing every time an object is picked from the bin) leads to inevitable complexities and challenges in the vision module of object stow task.
Along with the above, the challenges in camera placement, object localization and type of objects (variations in size, shape & reflection) are common to both tasks.
To pick an object (irrespective of the tasks specified above), a robot requires the exact location of the object. This data is generated using a 2D depth map created by a stereo vision camera. Camera placement plays a critical role in the effective performance of Vision module and robotic manipulation. The generic factors to consider while choosing the right camera are the enterprise product depth/breadth, lighting, temperature, and other environmental conditions.
Object localization brings in complexities in the case of the latter than the former, because of the involvement of cluttered scenes. The localization procedure involves identifying the location of the desired object in the scene, to facilitate object grasping by the robotic arm.
The object location is calculated in terms of its position and orientation, also called pose estimation. The estimated pose is a critical input for robotic arm automation.
In the below section, you will find a detailed description of the implementation of a pose estimation algorithm.
Pose Estimation
Open-Source Datasets
The retail specific open-source datasets for 3D object pose estimation are not widely available.
We use datasets like LINEMOD and YCB-Video throughout our experiments. These datasets deal with only a few retail objects. Also, we have captured an in-house dataset which includes 3 retail objects like a cereal box, coffee mug and soap box. This dataset capture is facilitated by Intel RealSense D435i camera and consists of images of individual objects and multiple objects in the scene.
Dataset Collection – In-house dataset generation
Pose estimation for every 3D object requires datasets comprising of both RGB and RGB-D images of objects with the corresponding ground truth values and transforms (rotation and translation). The common approach is to use multiple RGB-D sensors and high resolution DSLR cameras. However, such a setup requires a lot of resources and time.
To generate effective ground truth values with low-cost camera set up, we followed an approach of using aruco marker tags. The aruco marker tags are attached to the retail objects and the corresponding rotation and translation matrices are calculated using OpenCV methods with aruco markers.
Deep Learning Approach – Workflow and Results
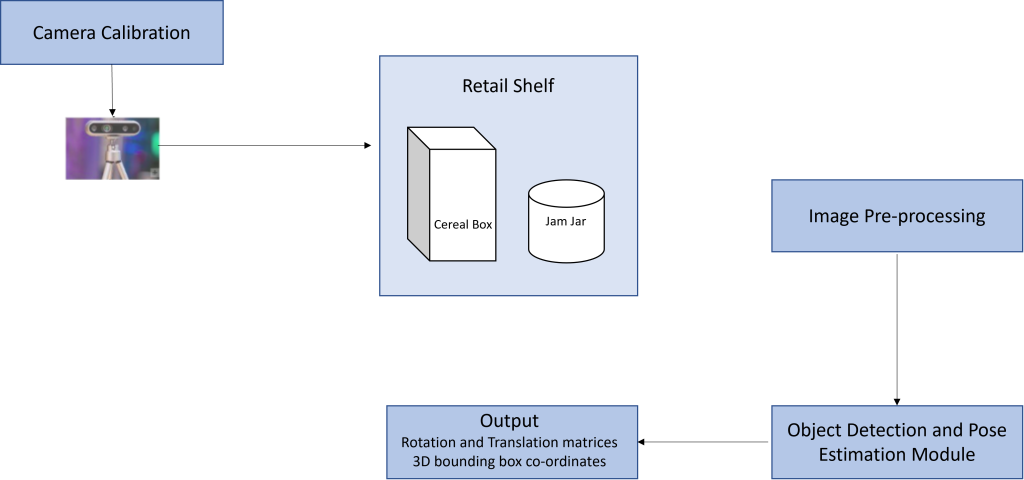
Pose estimation neural networks are widely categorized as pose regressor networks and 2D-3D correspondence networks. We use state-of-the-art pose estimation networks for our evaluation in different datasets. The basic workflow of our approach is as shown in fig 2.
Fig 2: Workflow of our approach
On LINEMOD dataset, for symmetric object (Egg box) and an asymmetric object (Driller), the measured Average Distance Difference (ADD) and translation errors are 0.6235 and 26.01 mm for the former and 0.75 and 17.04 mm for the latter. Below are a few of our visualization results evaluated on our implemented model for LINEMOD dataset.
Fig 3: Predicted 3D bounding box(blue) and ground truth(green) for Egg box (Image on left) and Driller (Image on right) on LINEMOD dataset
As proof of the generalizability of our deep learning models, we also present the visualization results on our in-house dataset.
Fig 4: Predicted 3D bounding box (in green) for the objects in our in-house dataset
With the ever-increasing SKU (stock keeping units) range, real-time dataset collection procedure has become extremely complicated.
Owing to the data-centric AI approach, high quality data can be artificially generated and labelled. This synthetic data can be used for further training and testing of the model, leading to better overall performance results.
Accelerated mobile cobot deployment using digital twin and synthetic data
Any kind of simulation; whether it is data or a physical entity (fulfillment center floor, in our case) is an inexpensive alternative to real-world procedures. On one hand, synthetic data is the simulation of real-world data for AI models. While on the other hand, digital twin is a cost-effective simulation of physical space, people, and processes. Synthetic data when used in conjunction with digital twin effectively accelerates the validation for robotic systems and thus, eventually leads to predictive maintenance.
Fig 4: A labeled synthetic data sample, sourced from Unity3D [6]
Conclusion
As cobots are being touted as the next wave in warehouse automation, tmhe need for computer vision in mobile cobots is a necessary technology for automating tasks like pick and stow, packaging and many others in warehouses which (otherwise) would have simply not been possible.
With the advent of mobile cobots in retail fulfillment centers, there is increased traction for expertise in Robotics in collaboration with AI (Artificial Intelligence).
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
Introduction
The cryptocurrency marketplace is no longer a fringe frontier; it’s a fiercely competitive, round-the-clock battlefield. The ceaseless flux of Bitcoin, Ethereum, and countless altcoins presents entrepreneurs with…
The insurance sector has started to witness the digital transformation, and artificial intelligence (AI) is right in the middle of it. Insurance companies relied on manual underwriting, predicated pricing, and reactive customer support for…
The last five years have seen more significant changes in digital marketing than the previous twenty years. With only a few clicks, Artificial Intelligence (AI) tools can now write, design, analyze, and optimize campaigns, which is at the core of…
Ever wonder how your favorite apps seem to get what you’re looking for, like suggesting the perfect song or product? That’s where vector databases come in. They’re a smart way to handle data, making searches and recommendations faster and more…
Imagine a world where artificial intelligence (AI) is no longer just a tool—but a teammate or co-pilot or sidekick. Where business systems think, act, and adapt with a level of autonomy once thought to be the domain of science fiction. This isn’t…
AI is evolving fast—but it’s hitting limits. Not because models aren’t powerful enough, but because the data feeding them isn’t keeping up. Whether you’re training a chatbot, building a recommendation system, or deploying a self-driving car, the…