The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
In recent years, digitalization revolutionized the entire economy. Banks— as the facilitators, were at the heart of the shift. In India, digital transactions have increased from 31 billion to 103 billion in the last 5 financial years. As a PwC report stated, UPI transactions alone are expected to reach 1 billion per day by 2026-27. Globally, the digital payment market is expected to grow at a CAGR of 14.3%.
One of the driving factors behind this has been the revolution in the telecommunication industry, which contributed to the wild adoption of smartphones with cheaper internet data. As a result, customers are uniquely positioned to leverage best-in-class digital services, introducing a new challenge for digital service providers to meet skyrocketing customer expectations.
To adapt to this sudden explosion of digitization and changing behavior of customers, the banks are in the hot seat. It needs to seamlessly cater to the continuously growing digital traffic and transaction volume, placing customer experience at the core. This explains the increasing trend of major incidents and outages across the banking industry, which keeps flashing in the news and social media. As per NPCI data, TD (Technical decline) of UPI transactions is contributing up to 5% of total transactions. Only for UPI, there have been 110 major incidents in March 2023 where each of the incidents caused the outage of more than 30 Min or declined 3 Lac+ transactions. Contributors are spread across all banks. Hence inevitably regulatory bodies have tightened the compliance requirement for the banks to minimize outages and failures to protect customers.
Chaos Engineering for Digital Immunity
Technology transformation has become inevitable to ensure effective end-to-end digital service delivery. However, the rapid adoption of cloud, distributed architecture and cloud-native development programs have exposed potential vulnerabilities in distributed and complex integrated systems.
Chaos Engineering is a breakthrough in building the digital immunity of IT systems. “Digital Immunity System” is in Gartner’s Top strategic technology trends for 2023 and they predict that “by 2025, 40% of organizations will implement chaos engineering practices as part of SRE initiatives.”
In the broader spectrum of application reliability (SRE), resiliency plays a vital role. Resiliency can be closely envisioned as immunity, which determines the ability of IT systems to continue operations even in case of unforeseen disruptions.
What is Chaos Engineering?
The very first step to address a problem is to acknowledge the problem that “Things Break”. Chaos engineering is a disciplined approach of injecting failures to discover vulnerabilities within a distributed system. Chaos engineering performs wide, careful and unpredicted experiments to generate new knowledge about the system’s behavior, properties and performance. It checks the system’s capability to survive against unstable and unexpected conditions. The objective is to identify and fix possible failures before there are outages in production and end up in the news.
Due to the increasing complexity and distributed nature of modern IT systems, it’s almost impossible to ensure 100% reliability through traditional testing methods. Through chaos engineering, we can-
Confirm known knowns: When a node fails, it will be removed from the cluster and a new node will be added to the cluster
Understand the unknowns: When a node fails and gets replaced in the cluster, what is the impact on user transactions during a peak usage period
Discover unknown-unknowns: What is the impact on application availability and recovery time when an entire cluster in a region goes down
Increased availability and decreased MTTR are the two most common benefits of chaos engineering. Through regular chaos engineering experiments, organizations can achieve four nines of availability and MTTR under one hour. This also helps in preparedness to respond to failures. Overall, chaos engineering can boost customer experience and build confidence in system behavior
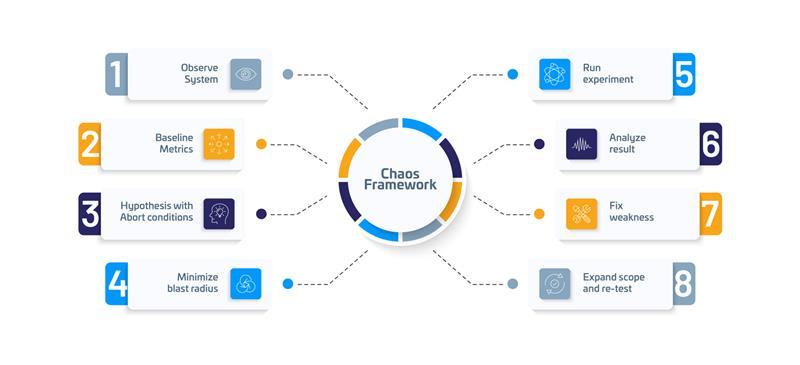
Chaos Engineering Framework
The following diagram explains a systematic approach to conducting chaos engineering.
A baseline of normal or steady-state behavior of the system must be established before conducting chaos tests. In production, existing APM or observability solution can be leveraged for this. In Pre-production, this can be established through performance tests with an accurately designed workload model representing production behavior.
Building a hypothesis is the key to designing effective chaos experiments. A hypothesis describes the expected system behavior as per architecture and application design. For example, if one of the PODs goes down in a multi-pod service deployment, other PODs will continue serving requests and new POD will spawn up to replace the failed POD.
Another example: If latency of Service-B goes beyond 200 ms, the request originating Service-A will timeout and initiate retry. After 2 failed retries, the transaction will timeout and show a pre-defined static response to the end user”. This is also an example of graceful degradation.
During the chaos experiments, variables will be injected into the system to prove or disprove the hypothesis. The objective is to learn more about the system behavior.
It is always advisable to plan chaos experiments at a small scale in a controlled manner and eventually expand the blast radius.
Mapping Chaos engineering with product lifecycle
Chaos engineering experiments are to be exercised in production on a regular basis. But that can be targeted as an end-state of an organization’s chaos engineering journey as it requires utmost maturity in process, technology framework and mindset. With a continuously increasing focus on application reliability, chaos engineering adoption has shifted left (Pre-production/ Staging) to go hand-in-hand with reliability and observability-driven development. This also helps avoid major architectural or design related changes late in the game.
A recommended approach can be as follows:
Start chaos experiments in pre-production to identify and fix failures before the go-live
Automate chaos experiments and integrate with CI/CD pipeline to ensure continuous resiliency validation
Exercise controlled experiments in production when the system and processes are matured
Focus on risks that cannot be simulated in pre-production due to limitations/ dependencies
How do we identify and prioritize Chaos scenarios?
The key is to identify the probable points of failure in a complex and distributed architecture. FMEA (Failure Mode Effect Analysis) principles can be leveraged to a great extent to achieve the same. To prioritize the scenarios, each risk/ failure point can be associated with the severity of impact, probability of occurrence and detectability. Here are some of the guidelines to come up with scenarios:
A thorough analysis of the system architecture to identify a single point of failure from an infrastructure and design perspective. Example: Network load balancer (NLB), Application Load balancer (ALB), Message Queues, RDS, EC2, Network components etc.
Analysis of application journeys and data flows to determine the interdependency of services/ components that can cause application failures. Example, Enterprise service failures, 3rd party service failure, Cache failures, log overflow, Circuit breaker configuration, Certificate expiry, Authentication service failure etc.
Production incident analysis to identify high risks already identified in production and need focused attention. Example: OTP failures impacting all types of money movement.
KPIs to Measure for Chaos Engineering Experiments
Below enlisted are the KPIs to be referred while doing chaos experiments. Fixes to be implemented if any of the KPIs breach tolerance.
Availability (Uptime): Impact on application availability due to failure
MTTR: Mean Time to Restore a system after failure. i.e., when the system comes back to normal state
Response time/ Latency: Deviation in response time for impacted transactions/ services due to failure
Error rate: Percentage of failed transactions during restoration from failure
Throughput: Impact on transaction Processing Rate (TPS) during restoration time
Resource utilization: Impact on h/w resource utilization during failure. E.g. In a multi-node cluster, if one EC2 instance fails, utilization of other nodes should be within 80-85% to continue operations until the new instance comes up
With the highest ever growth rate of digital transactions coupled with the increasing complexity of modern distributed systems, failures have become unavoidable. Traditional testing methods are not sufficient to restrict production failures. Chaos engineering can help banks streamline their IT systems for minimal outages and faster recovery by better understanding system behavior during failures.
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
QualityKiosk Technologies is one of the world's largest independent Quality Engineering (QE) providers and digital transformation enablers, helping companies build and manage applications for optimal performance and user experience. Founded in 2000, the company specializes in providing quality engineering, QA automation, performance assurance, intelligent automation (IA) and robotic process automation (RPA), customer experience management, site reliability engineering (SRE), digital testing as a service (DTaaS), cloud, and data analytics solutions and services. With operations spread across 25+ countries and a workforce of more than 4000 employees, the organization enables some of the leading banking, e-commerce, automotive, telecom, insurance, OTT, entertainment, pharmaceuticals, and BFSI brands to achieve their business transformation goals.
The Three Lines of Defense (3LoD) model is a widely recognized framework for structuring roles and responsibilities related to risk management and control within an organization.
Originally positioned by the Institute of Internal Auditors (IIA) in…
In the intricate world of finance, financial institutions rely heavily on models to navigate the complexities of risk and opportunity. Financial modeling helps banks and other financial institutions in decision-making, risk management, and strategic…
Cloud repatriation is emerging as a strategy to address the challenges of public cloud adoption, including cost escalation, security compliance, vendor lock-in, and data sovereignty.
Cloud computing has transformed business operations with…
These days, customers expect personalized attention, and becoming a customer-centric business is no longer an option but a necessity.
For the insurance sector, hyper-personalization has emerged as a game-changer. By using advanced analytics, smart…
In recent times, large language models (LLMs) have revolutionized the field of natural language processing, demonstrating impressive capabilities in understanding and generating human-like text. However, when it comes to sensitive and complex…
The traditional accounts payable (AP) process involves human agents performing manual entries of invoices, payment processing, and approvals.
However, with the rapid increase in transaction volumes, manual AP workflows begin leading to issues and…