The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
A high-level view of the popular open-source distributed big data processing platform and its integrations.
Unlike the relational database era, recent times have revolutionized the end-to-end data pipeline from data generation, data collection, data ingestion, data storage, data processing, data analytics, and the cherry on top, machine learning and data science. The first platform for handling large volumes of data with respect to distributed storage and parallel processing was Apache Hadoop (It is very popular now as well). In this short blog, I will try to paint a high-level picture of Apache Hadoop and the most popular integrations.
Let’s look at some history
Hadoop was created by Doug Cutting and Mike Cafarella in 2005 based on Google File System paper that was published in October 2003. It was originally developed to support Apache Nutch (an open-source web crawler product) and later moved to a separate sub-project. Doug, who was working at Yahoo! at the time named the project after his son’s toy elephant :) Later in 2008, Hadoop was open sourced, and The Apache Software Foundation (ASF) made Hadoop available to the public in November 2012.
What makes Hadoop special
The core idea behind Hadoop was to process large volumes of data in a distributed way using commodity hardware. It was also an assumption that hardware failures can occur frequently and the software should be capable of handling these and providing fault tolerance. Commodity does not mean cheap, non-usable hardware. It just means that it is relatively inexpensive, widely available and basically interchangeable with other hardware of its type. Unlike purpose-built hardware designed for a specific IT function, commodity hardware can perform many different functions (same hardware can be used to run a web-server, a Linux server, an FTP server, etc.)
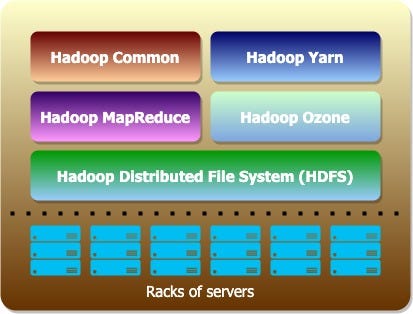
Image 1 : Core modules of Apache Hadoop
Hadoop can be configured to run on a single server (for development and testing purposes) and on full scale multi node setup (production scenarios). In any case, the core components for Hadoop are:-
Hadoop Distributed File System (HDFS)
HDFS is a highly fault-tolerant distributed file system and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets
HDFS has a master-slave architecture with a NameNode (master) and number of DataNodes (slaves). HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks (128MB sized) and these blocks are stored in DataNodes. NameNode manages the metadata which is the mapping of blocks to the DataNodes. For fault tolerance, a single file block will have multiple copies (default 3) and they will be stored in multiple DataNodes. Let’s look how a read and write happens in HDFS at high-level.
Image 2 : Read and Write flow in HDFS
Hadoop MapReduce
It is a framework for easily writing applications that process vast amounts of data (multi-terabyte data-sets) in parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
MapReduce application consists of three different tasks. A mapper task, a reducer task and an optional combiner task. The mapper task processes the input file by splitting it into independent chunks and processes them in parallel. The number of mappers depends on the number of InputSplits. InputSplit is the smallest data chunk that can be processed independently, which will be a multiplier of the HDFS data block (128MB). The reducer takes the outputs of all mapper tasks, sorts the results and then generates the final output. The combiner task is known as a semi-reducer which does a small combined operation on the mapper side itself. This is done to reduce the data volume before the reducer picks it up.
Hadoop YARN (Yet Another Resource Negotiator)
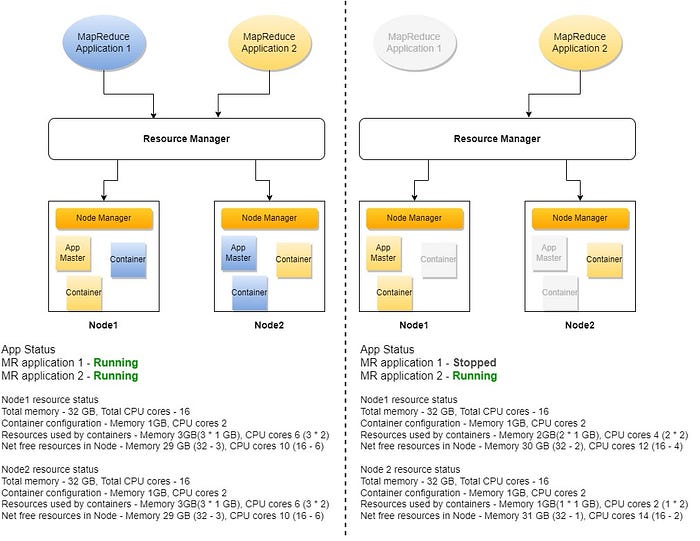
Interesting name, isn’t it? YARN takes care of the resource management in Hadoop cluster. Any application that tries to run on the Hadoop cluster can get the required resources (CPU cores and memory) from YARN.
The smallest unit of resources that YARN can allocate is known as a container. The container is similar to an actual server. Both have a number of CPU cores and finite memory. But the server is physical and the container is logical, meaning there can be many containers allocated in a single server. The memory and CPU allocated to a single container is based on YARN configuration properties.
Lastly, let’s look quickly at the core services in YARN
Resource Manager (RM): Central authority who allocates containers for all applications Node Manager (NM): Service running on each server on the cluster and responsible for containers, monitoring their resource usage, and reporting the same to Resource Manager Application Master (AM): As per application service which negotiates containers from RM for that specific application. AM itself runs as a container.
Image 3 : Overview of application resource allocation by YARN
Hadoop Commons and Hadoop Ozone
Hadoop Common provides a set of services across libraries and utilities to support the other Hadoop modules.
Ozone is a scalable, redundant, and distributed object store (Such as AWS S3 or Azure Blob storage) for Hadoop which can scale to billions of objects of varying sizes.
The ecosystem of rich integrations
So far, the focus has been on the core components. Let’s shift the focus a little bit to look at some of the very popular integrations runs on top of Hadoop which elevates Hadoop to an enterprise data platform.
Image 4 : Hadoop and popular integrations
Data movement Apache Flume: A distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data from a variety of sources to HDFS Apache Sqoop: Dataimporting and exporting service for structured data to and from HDFS. Typically, the input and output sources will be RDBMS systems Apache Storm: A distributed real-time computation system. Apache Storm makes it easy to reliably process unbounded streams of data, a.k.a real-time processing
Data processing Hive: Hive is data warehouse software that facilitates reading, writing, and managing large datasets residing in distributed storage (such as HDFS) using SQL programming Pig: Pig is data processing framework that is powered by a proprietary scripting language (Pig Latin) for reading, writing, and processing data stored in HDFS Tez: Apache Tez is a framework comparable to MapReduce. It provides better performance than MR as intermediate results will not be stored on disk, but rather in memory. In addition to this vectorization is also used (processing bulk of rows rather than a single row at a time)
Hive and Pig make use of either MR or Tez for running data processing jobs
Security Kerberos: In an on-premise Hadoop cluster setup, Kerberos is used as the authentication mechanism within the cluster components and between external services and Hadoop Ranger: Ranger the service for authorization across all Hadoop components. Ranger enables security policies varying from directory, file, database and table access as well as fine-grained access to tables
Oozie It is a workflow scheduler running on the Hadoop platform. Oozie is integrated with the rest of the Hadoop stack supporting several types of Hadoop jobs out of the box
Spark An in-memory computation framework that provides batch and real-time data processing capabilities along with machine learning and graph data processing capabilities
Data stores & Query engines Impala:A massively parallel processing, highly performant SQL query engine with in-memory processing capabilities to provide very low latency results on large data volumes Druid: A column-oriented, distributed data store whose core design combines ideas from data warehouses, timeseries databases, and search systems to create a high-performance real-time analytics database HBase & Phoenix:HBase is a NoSQL, distributed column-oriented data store which provides random read/write access capabilities on big data.
Phoenix is an SQL query engine that runs on top of HBase which provides OLTP capabilities to perform various types of querying patterns
File formats Avro: It is a row-oriented data serialization format that uses JSON to define the schema and creates compact binary data when serialized. It supports full schema evolution ORC (Optimized Row Columnar): It is an optimized column-oriented data storage format mainly used in Hive. It also enables Hive to have transactional capabilities similar to OLTP database Parquet: Similar to ORC, it is another column-oriented data storage format that is widely used with various data processing platforms such as Apache Spark
Zeppelin A web-based notebook which brings data exploration, visualization, sharing and collaboration feature to Hadoop used by data analysts, data scientists, etc. for data exploration
Superset A powerful web-based data visualization platform that provides rich visualization and dashboarding capabilities with connectivity to Hive, Druid, HBase and Impala and other data stores
Ambari Central management service for Hadoop which enables provisioning, managing, and monitoring Apache Hadoop clusters
Atlas An open-source metadata management and governance system designed to help enterprises easily find, organize, and manage data assets in the Hadoop platform
Zookeeper It is a distributed coordination service that helps to manage a large number of hosts such as the Hadoop cluster
Hadoop enterprise
CDP (Cloudera Data Platform)
AWS EMR (Elastic MapReduce)
Azure HDInsight
Google Cloud Dataproc
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
NeST Digital, the software arm of the NeST Group, has been transforming businesses, providing customized and innovative software solutions and services for customers across the globe. A leader in providing end-to-end solutions under one roof, covering contract manufacturing and product engineering services, NeST has 25 years of proven experience in delivering industry-specific engineering and technology solutions for customers, ranging from SMBs to Fortune 500 enterprises, focusing on Transportation, Aerospace, Defense, Healthcare, Power, Industrial, GIS, and BFSI domains.
Enhancing Supplier Performance and Risk Management with AI/ML
“Advanced AI supplier performance tools and machine learning in procurement are transforming risk management and supplier evaluation. Predictive supplier…
Introduction
Data has evolved into a core asset for modern enterprises, but its true value lies not in volume, but in how it’s utilized. Enterprise Data Analytics enables organizations to extract insights from massive datasets, supporting better…
Running a business isn’t just about driving revenue — it’s about managing money smartly. And one of the most overlooked yet mission-critical areas is cash flow management. If you’re a business owner or decision-maker, you might already know “Why…
AI is no longer just a tool—it’s becoming a decision-maker in its own right. But decision-making without accountability is a risk.
By Rizwan Shaikh, Senior Director, Expleo
While technology evolves at a rapid pace, businesses are…
Authored by: Avinish Agarwal, Director - Delivery, Xoriant
We live in an age where data is abundant—but clarity is rare. Organizations are flooded with information, yet many still struggle to turn insights into outcomes. The issue isn’t a…
Artificial intelligence (AI) is altering our lives and businesses for good by enhancing experiences and simplifying tasks. When did you last go to a bank to make deposits, transfer money, or for KYC? It is tough to recall, as AI has brought each of…