The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
Unlocking the power of Delta Lakehouse in Kubernetes is a journey through the realms of data lakes and container orchestration. In this blog post, we’ll explore the seamless integration of Delta Lakehouse into Kubernetes, unraveling the potential it holds for data-driven applications and workflows. Whether you’re a data engineer, developer, or simply curious about the intersection of big data and containerization, fasten your seatbelts as we dive into the fascinating world of Delta Lakehouse in K8S.
Delta Lakehouse, built on top of Apache Spark, brings reliability and performance to data lakes by providing ACID transactions and scalable metadata handling. In the context of Kubernetes (K8S), this technology brings a new dimension to managing and processing large-scale data within containerized environments.
Why Delta Lakehouse in Kubernetes?
Kubernetes, commonly known as K8s, has emerged as the industry standard for container orchestration. It offers a robust platform for deploying, managing, and scaling containerized applications. Its dynamic capabilities make it particularly well-suited for data lakes, allowing organizations to efficiently handle evolving data processing requirements. By harnessing Kubernetes, businesses can take advantage of automatic scaling, fault tolerance, streamlined resource allocation, and simplified deployment of data processing workloads.
Understanding Data Lakehouse
Before diving into the world of data lakehouses in Kubernetes, let’s quickly recap what a data lakehouse is. A data lakehouse is a unified data storage architecture that combines the strengths of data lakes and data warehouses. It provides a single repository for storing structured, semi-structured, and unstructured data, making it ideal for handling diverse data types and formats. Data lakes offer schema enforcement, ACID transactions, and support for both batch and real-time analytics, allowing organizations to run complex queries and perform advanced analytics on large datasets without compromising performance.
Setting Up Delta Lakehouse in Kubernetes
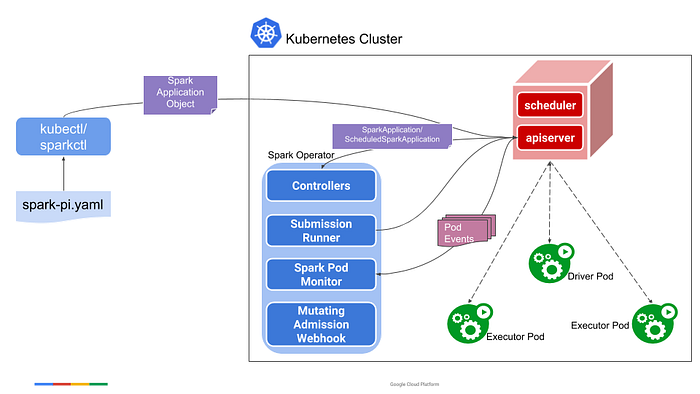
To establish Delta Lakehouse in Kubernetes, utilizing the Spark Operator streamlines the deployment and management of Spark applications interacting with Delta Lake. After installing the Spark Operator, define a SparkApplication custom resource specifying key parameters. Submit your Delta Lake application as a Spark job, prompting the Spark Operator to deploy and manage the Spark cluster dynamically. This automated process includes monitoring the application’s status, adjusting resources based on workload changes, and ensuring optimal efficiency. The integration provides a robust, scalable, and containerized solution for handling significant data processing tasks within Kubernetes. Subsequent sections will delve into specific configurations and practical use cases to maximize the potential of Delta Lakehouse in the Kubernetes environment.
The diagram shows how different components interact and work together.
Deploying Spark jobs in K8s
For installing the Spark application in K8s, we use the Spark operator. The Spark operator is a K8s native tool that helps us run Spark applications on K8s clusters. It simplifies the deployment and management of Spark applications by providing a custom resource definition (CRD) that allows you to define Spark applications as Kubernetes resources. we deployed spark application for our project.
A walkthrough for running a Delta Lakehouse Spark application on Kubernetes.
We’re using Delta Lakehouse in Kubernetes, which combines the best parts of a data warehouse and a data lake. Delta Lakehouse can handle both structured and unstructured data. In this blog, we’re trying to set up Delta Lakehouse with the Spark Operator.
Here is a step-by-step guide on setting up a delta lake within a Spark application on Kubernetes.
Step 1: Create custom Docker images that include the necessary packages to run a Spark application with Delta Lake support.
Why might you want to create your own special Docker image?
The main reason for creating a custom Docker image, instead of using the default Spark Docker image, is to include additional packages required for executing the code. There were issues with running the packages and dependencies when adding them directly to the deps package in the YAML file. The primary problem that can result in a “ModuleNotFoundError” is the absence of required packages for import.
The packages used for creating Docker images in our project are as follows, but keep in mind that they may vary depending on your specific requirements.
Now the infrastructure is ready. Let’s run the spark job.
Step 3: Create a file as per format you have in mind, over here we are referring to spark-pi.yaml, which is readily available along with spark-on-k8s-operator GitHub, which we have modified for my use case.
Azure Blob Storage is a cloud-based object storage service provided by Microsoft Azure. It is designed to store and manage large amounts of unstructured data, such as text or binary data, like documents, images, and videos. Azure Blob Storage can be accessed using REST APIs or Azure SDKs, and it can be used to build applications that require scalable and durable storage for unstructured data.
Configuration (Azure Blob storage)
Here are the steps to configure Delta Lake on Azure Blob storage.
Data Lake Storage Gen2 converges the capabilities of Azure Data Lake Storage Gen1 with Azure Blob Storage. For example, Data Lake Storage Gen2 provides file system semantics, file-level security, and scale. Because these capabilities are built on Blob storage, you also get low-cost, tiered storage, with high availability/disaster recovery capabilities.
Configuration (ADLS Gen2)
Here are the steps to configure Delta Lake on Azure Data Lake Storage Gen1.
Include the JAR of the Maven artifact hadoop-azure-datalake in the classpath. See the requirements for version details. In addition, you may also have to include JARs for Maven artifacts hadoop-azure and wildfly-openssl.
Difficulties encountered while running Spark in AKS
when partitioning the data. Special characters cannot be used in directory names on Azure Storage.
An open error that prevents the reading of a delta log will occur when foreachbatch in PySpark is being used on Azure.
SparkPodSpec
The SparkPodSpec defines common elements that can be customized for a Spark driver or executor pod. In the following file, we customized the drivers and executors with respect to our resource requirements and computation time.
In conclusion, the strategic choice of Delta Lakehouse in Kubernetes aligns with industry standards, capitalizing on Kubernetes’ automatic scaling, fault tolerance, and resource efficiency. Throughout the setup process, the Spark Operator emerged as a pivotal tool, streamlining the deployment and management of Spark applications interacting with Delta Lake.
In summary, the synergy between Delta Lakehouse and Kubernetes holds immense potential for advancing data-driven applications and workflows. This convergence, at the intersection of big data and containerization, stands poised to shape the future of efficient and scalable data processing.
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
NeST Digital, the software arm of the NeST Group, has been transforming businesses, providing customized and innovative software solutions and services for customers across the globe. A leader in providing end-to-end solutions under one roof, covering contract manufacturing and product engineering services, NeST has 25 years of proven experience in delivering industry-specific engineering and technology solutions for customers, ranging from SMBs to Fortune 500 enterprises, focusing on Transportation, Aerospace, Defense, Healthcare, Power, Industrial, GIS, and BFSI domains.
Customer service remains a key driver to any organization irrespective of its size or type. Consumers in the current world seek ease, efficiency, and personal treatment by businesses. Alright, let me introduce you to the new heroes of…
The convergence of artificial intelligence (AI), cleantech, quantum computing, and the Internet of Things (IoT) is reshaping the digital ecosystem. For IT leaders, these technological advancements offer unparalleled opportunities to enhance…
The level of financial fraud has dramatically increased in recent years, ranging from credit card deception to insurance fraud. This surge highlights the urgent need to develop innovative procedures for identifying such cases. One of the…
In the first part of this blog, we looked at the complex challenges that the Indian healthcare sector currently faces – ranging from gaps in accessibility to issues with affordability and quality of care. We, then, examined ways in which some…
The healthcare ecosystem in India is at a pivotal moment, both for the economy and society. As the nation strives toward achieving its “Viksit Bharat @ 2047” vision, healthcare will be a foundational pillar in this transformation. With over 1.4…
Data today has become the lifeblood of enterprise operations. From customer insights to operational efficiencies, data drives decision-making across all levels of organizations. However, as the volume, variety, and velocity of data continue to grow…