The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
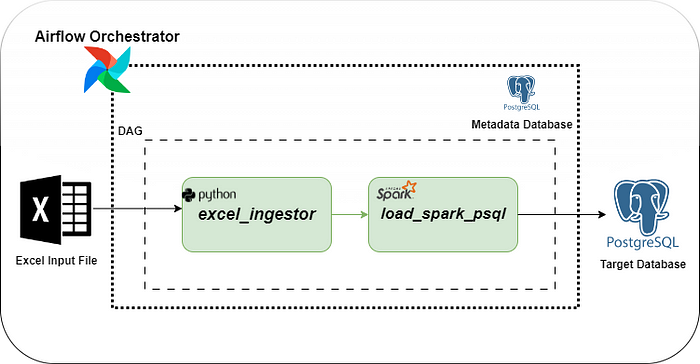
Apache Airflow serves as an open-source platform designed to develop, schedule, and monitor batch-oriented workflows. Leveraging its extensible Python framework, Airflow empowers users to construct workflows that seamlessly integrate with a wide array of technologies. This tutorial guides you through the process of crafting Apache Airflow DAGs to execute Apache Spark jobs.
The DAG comprises two tasks:
Task 1: the initial task reads an Excel file from the local environment, transforms it into a CSV file, and saves it to a specified output location in the local folder.
Task 2: The subsequent task reads the CSV file, applies additional transformations, and stores the results in a PostgreSQL table.
Required Steps for the Execution
1. Preparing an environment for Airflow in WSL
2. Prerequisites — WSL should be installed with PostgreSQL and PySpark
Preparing the environment for Airflow
For the current scenario, installing Airflow on WSL which involves the following steps:
Step 1: Make a new directory for Airflow, Update Package Lists and Install dependencies for Airflow.mkdir airflow
sudo apt update
sudo apt install -y python3 python3-pip python3-venv
Step 2: Create a Virtual Environment for Airflowpython3 -m venv airflow-venv
source airflow-venv/bin/activate
Step 3: Install Apache Airflow using ‘pip’pip install apache-airflow
By default, Airflow uses SQLite, which is intended for development purposes only. So for production scenarios, you should consider setting up a database backend to PostgreSQL or MySQL. For the current scenario, we are deploying PostgreSQL as a metadata database. The essential configuration modifications in the /airflow.cfg file within the /airflow directory, created during Airflow installation, governs settings like config files, log directories, and dags_folder where Airflow builds its DAGs.
Open the airflow.cfg by your preferred editor like vim.
The first thing you have to change is the executor which is a very important variable in airflow.cfg that determines the level of parallelization of running tasks or DAGs. This option accepts the following values:
· SequentialExecutor – which operates locally, handling tasks one at a time.
· LocalExecutor class executes tasks locally in parallel, utilizing the multiprocessing Python library and a queuing technique.
· CeleryExecutor, DaskExecutor, and KubernetesExecutor – For distributed task execution and improved availability these classes are available.
LocalExecutor is the preferred choice in this scenario, as parallel task execution is essential, and high availability is not a priority at this stage.executor = LocalExecutor
2. sql_alchemy_conn — This crucial configuration parameter in airflow.cfg defines the database type for Airflow’s metadata interactions. In this case, PostgreSQL is selected, and the variable is set as follows:sql_alchemy_conn = postgresql+psycopg2://airflow_user:pass@192.168.10.10:5432/airflow_db
Environment setup for PySpark and PostgreSQL for running Airflow
There are some basic setup needed for PostgreSQL and PySpark which includes,
PostgreSQL Environment Setup
You have to create the required user, roles, databases, schema, and tables in PostgreSQL for storing the metadata and the final output from Spark. Go to the Airflow venv and run,sudo apt upgrade
sudo apt install PostgreSQL
sudo service postgresql start
#to get superuser privileges in Postgres
sudo su – postgres
#create a superuser
CREATE USER [user] WITH PASSWORD ‘password’ SUPERUSER;
#command to interact with the PostgreSQL
psql
#for listing the users
\du
#for listing the databases
\l
Now create new DB’s for storing the metadata & spark outputCREATE DATABASE airflow_db;
CREATE DATABASE employee_details;
Now connect to the “etl_db” database and Create a schema and table in the “employee_details” table\c etl_db;
CREATE SCHEMA etl_db;
CREATE TABLE etl_db.employee_details (
Name VARCHAR(255),
Age INTEGER,
City VARCHAR(255),
Salary INTEGER,
Date_of_Birth DATE
);
Now run the below command,airflow standalone
This will initialize the database, create a user, and start all components.
To access the Airflow UI: Visit localhost:8080 in your browser and log in with the admin account details shown in the terminal.
Take another terminal go to airflow venv and run the commands for the required libraries for connecting Airflow with PostgreSQL.pip install psycopg2-binary
pip install apache-airflow-providers-postgres
Spark Environment Setup
go to the Airflow venv and install the Provider Package for Sparkpip install apache-airflow-providers-apache-spark
Install PostgreSQL-42.2.26.jar in airflow venvwget https://repo1.maven.org/maven2/org/postgresql/postgresql/42.2.26/postgresql-42.2.26.jarsudo chmod 777 postgresql-42.2.26.jar#to be used in the code to read the excel files
pip install openpyxl
Now start the Spark Cluster and set the local IP and master IP for Spark by running the below commands,export SPARK_LOCAL_IP=127.0.1.1
export SPARK_MASTER_IP=127.0.1.1
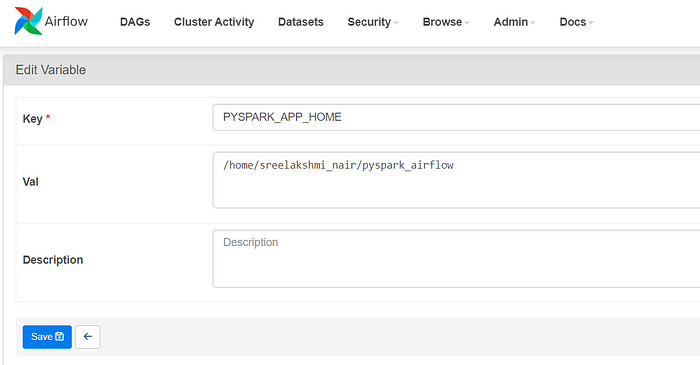
Set Spark app home variable in the Airflow UI — this is very useful to define a global variable in Airflow to be used in any DAG. Useful for getting this variable in code
· Go to Airflow UI’s Admin tab and then Variables,
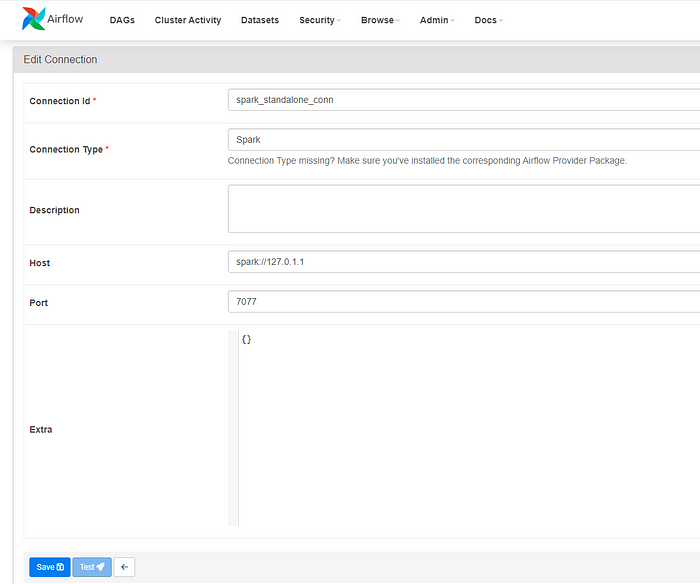
Set up a new connection for Spark in Airflow UI,
· Go to the Admin tab and then “Connections” and add a connection
How to Set Up the DAG Script
The DAG script orchestrates a data pipeline that involves the ingestion of Excel data, transformation using a PySpark application, and loading the transformed data into PostgreSQL.
· DAG Configuration:
The DAG is named ‘excel_spark_airflow_dag’ and is configured with default arguments such as the owner, start date, and email notifications on failure or retry.
· Excel Data Ingestion (PythonOperator):
The ‘excel_data_ingestion task’ is a PythonOperator that executes the transformXL function from the excel_ingestor module. This function reads an Excel file (input_data.xlsx), transforms the data, and saves it as a CSV file (output.csv). The task is set to run on a schedule of every hour (schedule_interval=”0 * * * *”).
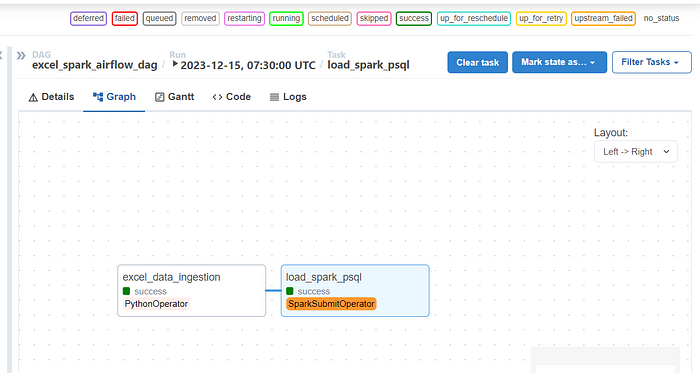
The load_spark_psql task uses the SparkSubmitOperator to submit a PySpark application (load_spark_psql.py). This application likely performs further transformations or processing on the data and loads it into a PostgreSQL database.
It is configured with parameters such as the Spark connection (spark_standalone_conn), executor cores, memory, driver memory, and packages required for PostgreSQL connectivity.
· Task Dependencies:
The excel_data_ingestion task is set to precede the load_spark_psql task (excel_data_ingestion >> load_spark_psql), indicating that the PySpark application should run after the Excel data has been ingested and transformed.
· Variable Usage:
The PYSPARK_APP_HOME variable is used to define file paths, and it is retrieved using Variable.get(“PYSPARK_APP_HOME”). Ensure this variable is defined in Airflow with the correct path.
· Timezone Configuration:
The DAG specifies the timezone as ‘Asia/Kolkata’ for scheduling purposes.
· Retry and Email Notifications:
The DAG is configured to retry on failure (retries: 0) and send email notifications on failure or retry.
Save the below code as excel_spark_airflow_dag.py in the DAG folder location
Now create the Python scripts “excel_ingestor.py” which contains “tranformXL” function and “load_spark_plsql.py” which contains “transformDB” function. Place these files inside the “pyspark_app_home” variable directory, and using this variable in the code we can access those files.
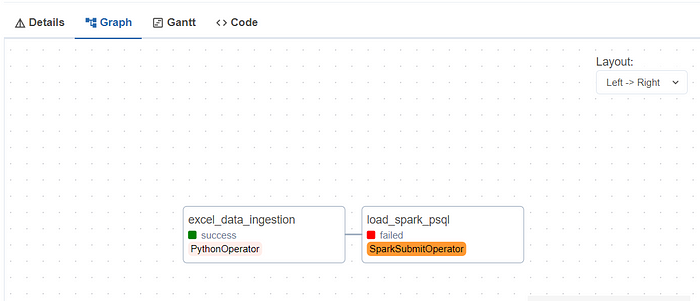
During the execution of the second task, errors were encountered, and these issues can be attributed to the following reasons:
Issue: Spark Cluster Configuration
It appears that the SPARK_LOCAL_IP and SPARK_MASTER_IP environment variables need to be set in the Airflow environment. In our current setup, Airflow attempts to execute the Spark code with the Spark cluster running locally.
Resolution Steps:
1. Navigate to the Spark sbin directory and Set the SPARK_LOCAL_IP and SPARK_MASTER_IPcd /opt/spark/sbin
export SPARK_LOCAL_IP=127.0.1.1
export SPARK_MASTER_IP=127.0.1.1
2. Start the Spark cluster
3. Rerun the DAG.
As you can see both the tasks ran successfully and there you have it — your ETL data pipeline in Airflow. We can see the output written in the PostgreSQL table,
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
NeST Digital, the software arm of the NeST Group, has been transforming businesses, providing customized and innovative software solutions and services for customers across the globe. A leader in providing end-to-end solutions under one roof, covering contract manufacturing and product engineering services, NeST has 25 years of proven experience in delivering industry-specific engineering and technology solutions for customers, ranging from SMBs to Fortune 500 enterprises, focusing on Transportation, Aerospace, Defense, Healthcare, Power, Industrial, GIS, and BFSI domains.
From the earliest programming languages to the present generation of programming languages, computer programming has come a long way. It has since become more powerful, efficient, and sophisticated. But the fundamental principles underlying…
Getting Started
Almost a quintillion bytes of data are produced daily, and it needs a place to go. A data pipeline is a set of procedures that process original data into usable information.
It is a crucial element of any system but is also…
Given ever-growing amounts of data and the challenges posed by data-intensive applications, implementing a modern data modeling approach has become important for all enterprises. A well-thought out data modeling strategy helps with faster time-to-…
Businesses are making rash, impulsive decisions as a result of an impending sense of doom in the market. Expenditures are reduced too low, new projects are halted, and employees are brutally laid off. While trying to navigate through a possible…
Data structures are specialized methods for arranging and storing data in computers so that actions on the stored data can be carried out more quickly. The use of data structures is widespread and varied in the domains of computer science and…
Purchasing insurance and knowing it’s your shield for all your precious possessions is like having a superpower, isn’t it?
Absolutely!
In today’s changing world, having insurance is like wearing a life jacket that assures financial security…