The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
The term bottleneck is very popular in the software engineering context and most of us are well aware of what it is. Simply put, it refers to the limitation of a single component in a system of multiple components, which restricts the performance and capacity of the overall system. A classic example running multiple applications simultaneously on a computer which at some point, throttles the CPU and the overall system performance suffers. If we look at an enterprise system, multiple applications can use the same database server and query requests beyond a certain limit can cause the DB server unable to fulfill the requests and finally failure of the system. We will find out why this is relevant in the context of a data mesh architecture.
A data lake, data warehouse and data lakehouse are some of the common implementation patterns to serve data analytics, BI reporting, data science and AI/ML use cases. Data warehouses started in the earlier days as the sole platform for data analytics requirements. Later came Data Lakes with a drastic increase in data volume and a variety of data types. Recently came Data Lakehouses where the characteristics of data lakes and data warehouses were combined for reducing operational complexity, data duplication and improving performance
The central data team in the organization slowly turning out to be a bottleneck.
Image 1: Central data team fulfilling data requests from multiple teams
The above diagram gives a very high-level view of a very familiar solution that a lot of organizations have implemented. This is a classic example where a central team of data engineers, platform engineers, analysts, etc. work in unison to deliver data products (it can be reports, dashboards, data APIs etc.) based on the requirements of multiple teams. Typically, this works with an intake process where the central data team gets the request, put it in their backlog and based on the resource availability and priority, the request will be fulfilled. Do you see a bottleneck here?
The central data team can be overwhelmed with requests from more and more teams and unable to fulfill requests on time.
Domain teams are the experts in their respective business areas and they know everything about the data. Still, the responsibility of generating value out of the data falls on the central data team.
Since the central data team creates data pipelines and related artifacts to deliver data products, failure to one component can cause data outages and SLA breaches for multiple domains.
Finally, it is always painful to generate value out of the data with no or very limited knowledge of what the data is. Of course, domain-specific business analysts can work with a central data team but as the organization grows, this can become very difficult to manage, hence bottleneck.
Growth of microservices-based architecture for enterprise applications
Microservices-based software solutions are on the rise. Typical monolith applications with a front-end, backend, and database are getting slowly replaced by event-driven microservice applications. Microservice-based solutions are a collection of services that are
Organized around business capabilities or domains
Independently deployable
Loosely coupled
Owned by small teams who are responsible for the business or domain
Wait a minute, so smaller teams, who are responsible for their own business or domain run the independent services in a microservice-based architecture. So why can’t the domain-specific teams own the data products as well, rather than relying on the central data team? It’s an interesting proposition and that’s exactly what Data Mesh is enabling.
Data Mesh — Core concepts
The term data mesh was coined by Zhamak Dehghani in 2019. The core concepts of it are explained in detail below
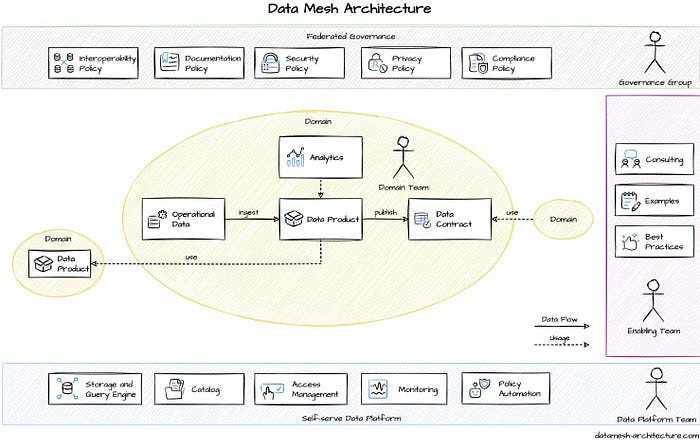
The core idea of data mesh architecture is decentralization and distribution of responsibility to the people who are closest to the data in order to support continuous change and scalability. Our organizations today are decomposed based on their business domains. Such decomposition localizes the impact of continuous change and evolution — for the most part — to the domain’s bounded context. Hence, making the business domain’s bounded context a good candidate for the distribution of data ownership. People within the domain own the analytical data, processing, metadata and everything related to serving the data product.
Data as a Product
OK, so we have domain-driven ownership for data and there are domain teams who are responsible for the data. But what do these teams produce? Data as a product is an autonomous logical component that contains all data, code, and interfaces to serve the domain team’s or other teams’ analytical data needs. You can think of a microservice for analytical data.
Data product is the node on the mesh that encapsulates three structural components required for its function
Code: This is the application source code that is deployed to fulfill multiple functions. Such as ETL, analytical SQL, data ingestion, API, ML application etc. within the domain Data and Metadata: Well, this is what we all need at the end. Data provides insights and value and metadata describes what the data is all about and its characteristics. Infrastructure and platform: Infrastructure components enable running the data processing jobs, and provides way of data storage such as object stores, messaging platforms etc. This can be any on-prem or cloud platform that can enable the data platform architecture
At the end of the day, we need quality data that can be served to meet the requirements within the domain or outside, along with the metadata
Data contract
Data contract complements the data product and defines the agreement between two parties for using a data product. Since domains own their data, if the data product owned by one domain needs to be accessed by another domain, data contract acts as a formal agreement. It can have characteristics such as details of serving and accepting parties, duration of contract, interface to access data product, conditions for cancellation etc.
Self-service data platform
Data platform is something on which everything is built upon. Typically, it is the infrastructure and the software components running on it. As an organization with many domain teams owning their data in place, setting up separate platforms for each of these domains can be an operational nightmare as well as hard to govern.
A self-service data platform in a data mesh architecture is owned by a central platform team with the proper abstraction of low-level internal implementation. This platform is available for all domains where they have their own private spaces in which they build their data products. An example of such a platform is the Kubernetes cluster where applications can be deployed as containers without worrying much about the implementation beneath the surface.
Federated governance
Governance is crucial in data mesh to set up appropriate rules and policies across the organization. Federated governance is a decision-making model led by the federation of domain data product owners and data platform product owners, with autonomy and domain-local decision-making power, while creating and adhering to a set of global rules — rules applied to all data products and their interfaces — to ensure a healthy and interoperable ecosystem.
A few examples of governance policies are.
How the external access endpoints for domain-owned data products should be set up for interoperability?
In what format are the data files to be used by an ML model to be set up?
How to request domain-specific space in the central self-service data platform?
The above ones are examples of global policies and there can be domain-specific policies applicable only to the domain.
Data Mesh — Practical implementation
Now let’s look at how to implement a data mesh architecture. First things first, unlike data warehouse solutions or data lake platforms (such as Snowflake or Databricks Lakehouse platform), you can’t purchase an enterprise data mesh product at least for now. But there are products and services that can be leveraged to implement a successful data mesh platform.
Assumptions
Applications in the organizations are fully containerized and all of them are running on Kubernetes cluster with event-driven microservice architecture
Cloud platform of choice is Microsoft Azure
Even though the applications are microservice-based, there are few systems running on legacy architecture.
Architecture
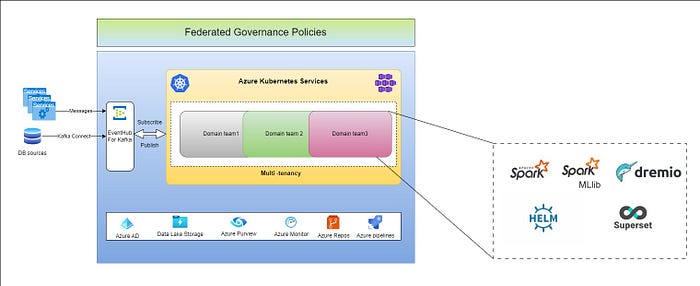
Image 2 : Data mesh architecture in MicrosoftAzure
Self-service data platform
Kubernetes cluster is the core of the data platform with complementary capabilities provided by other Azure services. Multi-tenancy can be achieved in the K8S cluster using Namespaces and other capabilities. Domain teams can develop data products using the below components.
Apache Spark — For data pipeline development (Deployed on K8S applications)
Apache Spark MLib — Machine learning jobs (Deployed as K8S applications)
Apache Superset — Dashboarding and reporting
Dremio — For ad hoc querying and analytics
Azure AD — Authentication
Azure Purview — Metadata and data catalog
Azure monitor — Monitoring
Azure repos and pipeline — Code deployment
Data contract
As mentioned earlier, this is where it is defined how the data is made available for external users (other domains in the data mesh)
EventHub — Streaming data published to subscribers
Azure Data Lake Storage — File/Table based data published for external users
Azure Purview — Metadata and data catalog
Data as a Product
Spark application for streaming and batch workloads
Spark ML jobs
Spark application deployments to K8S cluster using spark-on-k8s-operator
Dremio datasets (views and tables)
Dashboards/Reports/Alerts created in Apache Superset
Please note that this is just a reference implementation based on specific software components. Data mesh can be implemented using different platforms and technologies. There are many options but to implement a successful data mesh architecture, the priority should be given to core principles we discussed earlier.
Things to remember
Data mesh is not for everyone. As you can see, it brings in additional responsibilities to the domains. If you are a very small organization you may be better off with a central data team serving all data requests. Implementing data mesh in an existing enterprise may require a good level of refactoring of the existing architecture. On top of this, creating and managing data pipelines, analytics, optimization etc. are a different set of skill sets. Building these capabilities within the domain is a cultural shift and ultimately needs skilled resource onboarding or upskilling existing resources.
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
NeST Digital, the software arm of the NeST Group, has been transforming businesses, providing customized and innovative software solutions and services for customers across the globe. A leader in providing end-to-end solutions under one roof, covering contract manufacturing and product engineering services, NeST has 25 years of proven experience in delivering industry-specific engineering and technology solutions for customers, ranging from SMBs to Fortune 500 enterprises, focusing on Transportation, Aerospace, Defense, Healthcare, Power, Industrial, GIS, and BFSI domains.
Enhancing Supplier Performance and Risk Management with AI/ML
“Advanced AI supplier performance tools and machine learning in procurement are transforming risk management and supplier evaluation. Predictive supplier…
Introduction
Data has evolved into a core asset for modern enterprises, but its true value lies not in volume, but in how it’s utilized. Enterprise Data Analytics enables organizations to extract insights from massive datasets, supporting better…
Running a business isn’t just about driving revenue — it’s about managing money smartly. And one of the most overlooked yet mission-critical areas is cash flow management. If you’re a business owner or decision-maker, you might already know “Why…
AI is no longer just a tool—it’s becoming a decision-maker in its own right. But decision-making without accountability is a risk.
By Rizwan Shaikh, Senior Director, Expleo
While technology evolves at a rapid pace, businesses are…
Authored by: Avinish Agarwal, Director - Delivery, Xoriant
We live in an age where data is abundant—but clarity is rare. Organizations are flooded with information, yet many still struggle to turn insights into outcomes. The issue isn’t a…
Artificial intelligence (AI) is altering our lives and businesses for good by enhancing experiences and simplifying tasks. When did you last go to a bank to make deposits, transfer money, or for KYC? It is tough to recall, as AI has brought each of…