The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
So, you have decided to go in for a data modernization exercise, which befits any forward-thinking organization. That’s the good news!
The question now is what is the way forward? What is the most appropriate model for your organization?
The truth is that there is no one-size-fits-all solution. Over the last decade, Data Lakes grew to be the de facto model for modernization. These days, they are being supplanted by, or in many cases have been subsumed into, Data Meshes. Both models have their votaries, and both come with their own set of challenges.
Let us examine these two models in a little more detail so that you can wrap your mind around them more easily and be better positioned to choose between them.
The Data Lake
A Data Lake is a large reservoir into which raw data can be poured and stored until needed. Thanks to its flat architecture, it stores data in its native format, as binary large objects (blobs) or files. It takes in unstructured data, such as emails, documents, etc.; binary data like images, audio, and video; semi-structured data, such as CSV, logs, and XML; and structured data from relational databases. The extract-transform-load process happens within the Data Lake itself.
The Data Lake can, therefore, efficiently manage the high Volume, high Variety, and high Velocity of Big Data. It also significantly enhances the value of Big Data by making it available as reports, dashboards, and applications, to facilitate better visualization, advanced analytics, and machine learning. All, of course, to ultimately empower organizations with the ability to take evidence-supported business decisions with more far-reaching impact than ever before.
Being a single, integrated, and complete system, the Data Lake facilitates faster and simpler development of applications as well, which are based on one code.
Let's see a use case scenario where a leading full-service aviation company wanted to transform its service operations. Leveraging Microsoft, an integrated Data Lake was created on MS Azure with the following scope:
Single-Source of truth and 360-view of key entities across the enterprise.
“Day of Ops” applications
Leverage AI/ML for better resource planning, safety, and cost optimization
Self-Service BI and Better Data Governance, Security, and Privacy
Batch Data Ingestion into Snowflake Data Warehouse using tool Dell Boomi, ADF pipeline, and Azure Databricks.Real-time data ingestion and Reporting tool developed using Azure Event Hub, Azure Stream Analytics, Azure SQL, and Azure PowerBI
Data quality framework integrated with Batch Data ingestion framework.
The impact that was delivered:
Completely automated mechanism to ingest Batch data at a scheduled time.
Rich in-stream data cleansing and preparation capabilities to ensure timely delivery of consumption-ready data.
A large number of built-in integration with source and destination systems.
Real-time dashboard reporting capability
The Data Lake can reside on the cloud, on a platform such as Microsoft Azure, or as a distributed file system such as MS SQL Server with the Hadoop Distributed File System.
However, Data Lake also has its drawbacks.
As the volume of data increases and grows more complex, the central IT function becomes overloaded with requests and cannot keep pace. Individual project teams then try to bypass it and deploy quick fixes that are poorly integrated and create problems in the future.
What is worse, organizations keep pouring data into the Lake and eventually lose track of what it contains. Much valuable information can go unnoticed because data analysts have no knowledge vis-à-vis the data’s source domain and engage in fishing expeditions.
Many organizations have seen their Data Lakes turn into data swamps because, after a point, it entails considerable technical and organizational effort to make productive use of them.
The Data Mesh
The Data Mesh evolved in response to the many challenges that the Data Lakes posed.
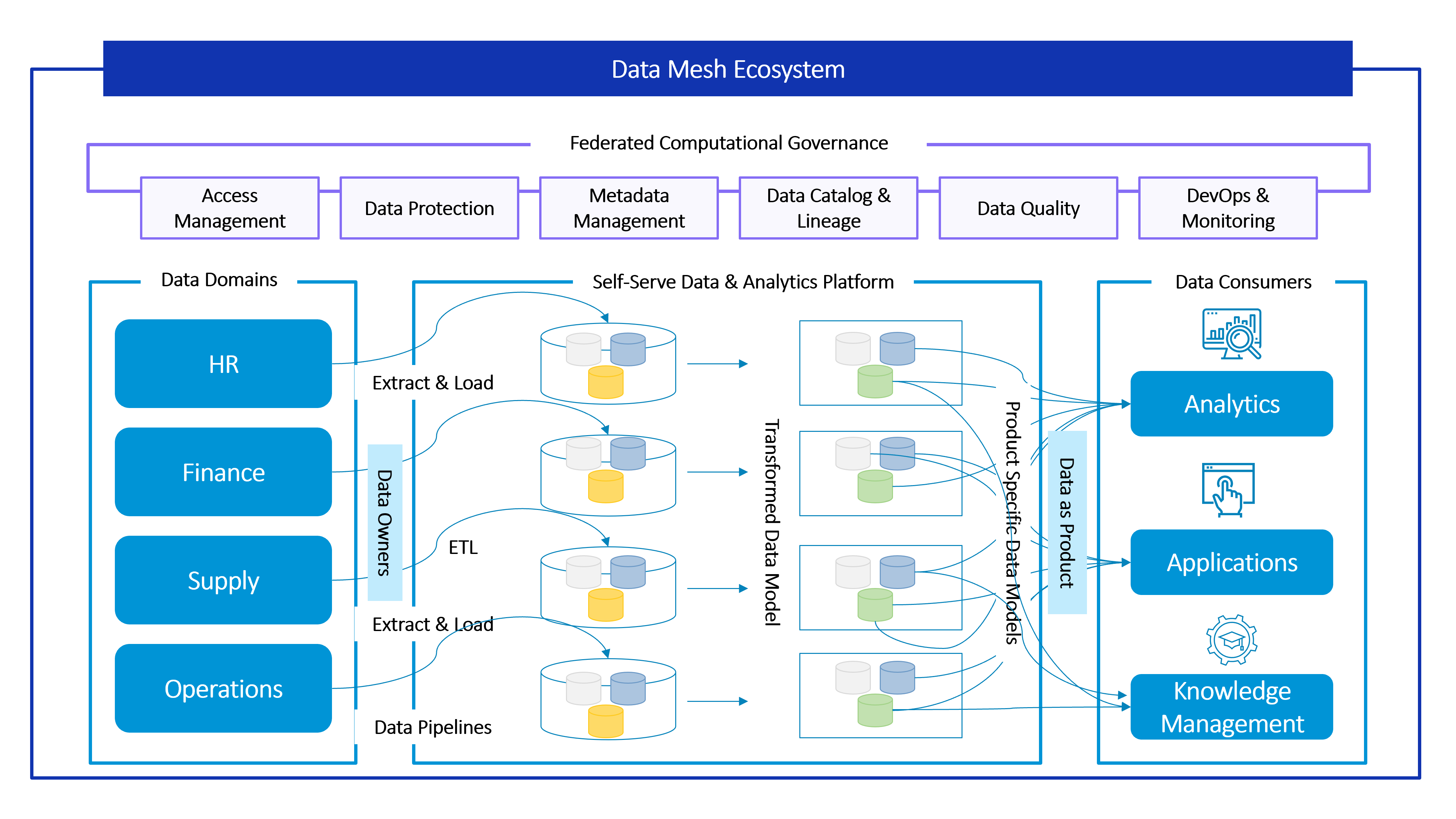
Unlike the Data Lake, the Data Mesh is a composite ecosystem, not a monolith. It breaks giant, monolithic enterprise data architectures into decentralized subsystems, each owned and managed by a dedicated team.
The Data Mesh facilitates the management, connection, and smooth flow of data from producers through to consumers, whether outside or within a Data Lake. In that sense, a Data Mesh may include Data Lakes.
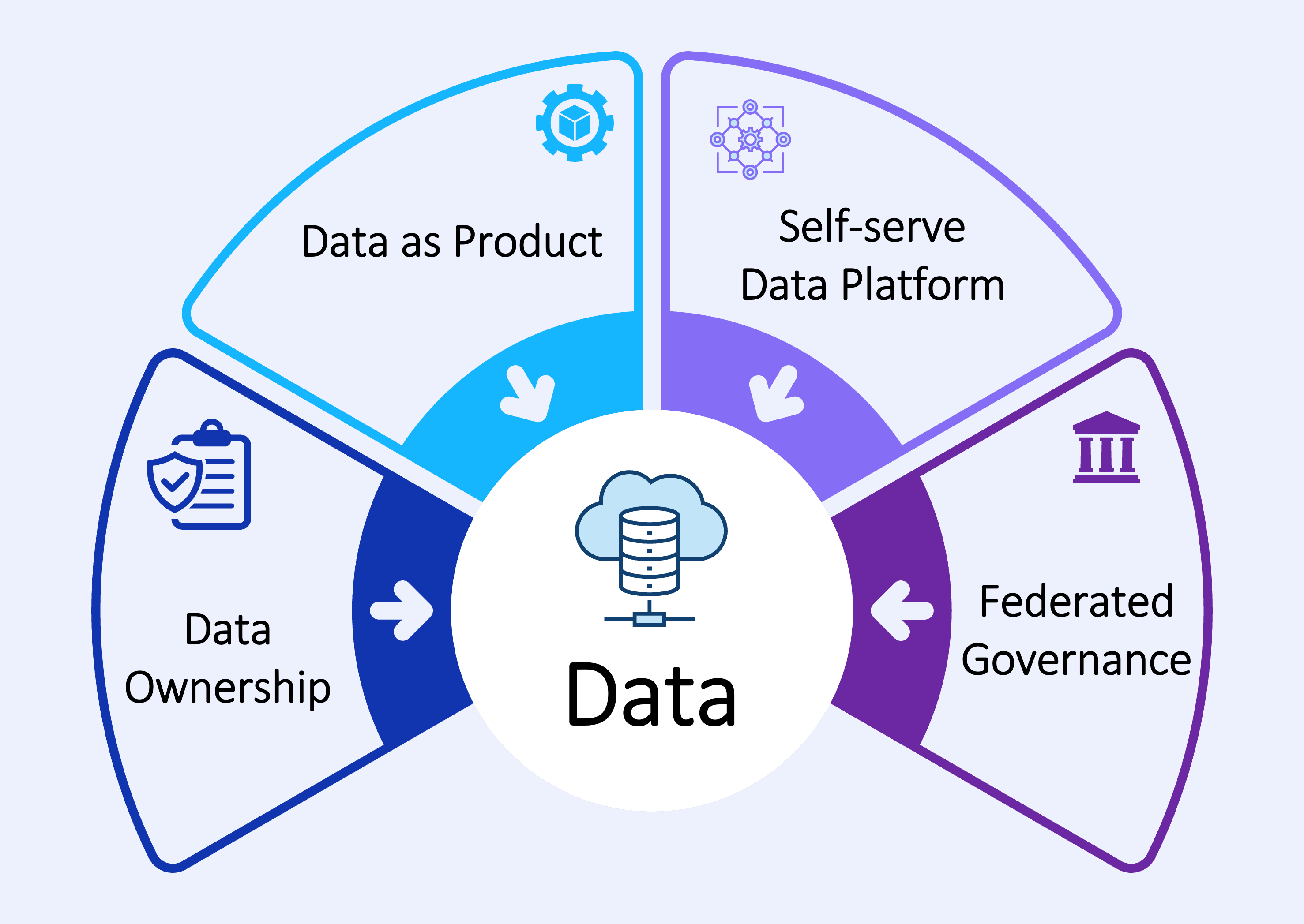
Data Meshes can be said to have four pillars:
Decentralized Data Ownership: Data is owned by the entity that produces it, typically functions such as HR, Finance, Marketing, etc. Therefore, more value can be derived from it. Typically, tools such as Azure Databricks are used to process large workloads of data.
Data as Product: Users, such as data analysts, can easily source data directly from the domain owners, who will ensure that the data is of high quality. Conflicts are eliminated by using approaches like event sourcing and CQRS.
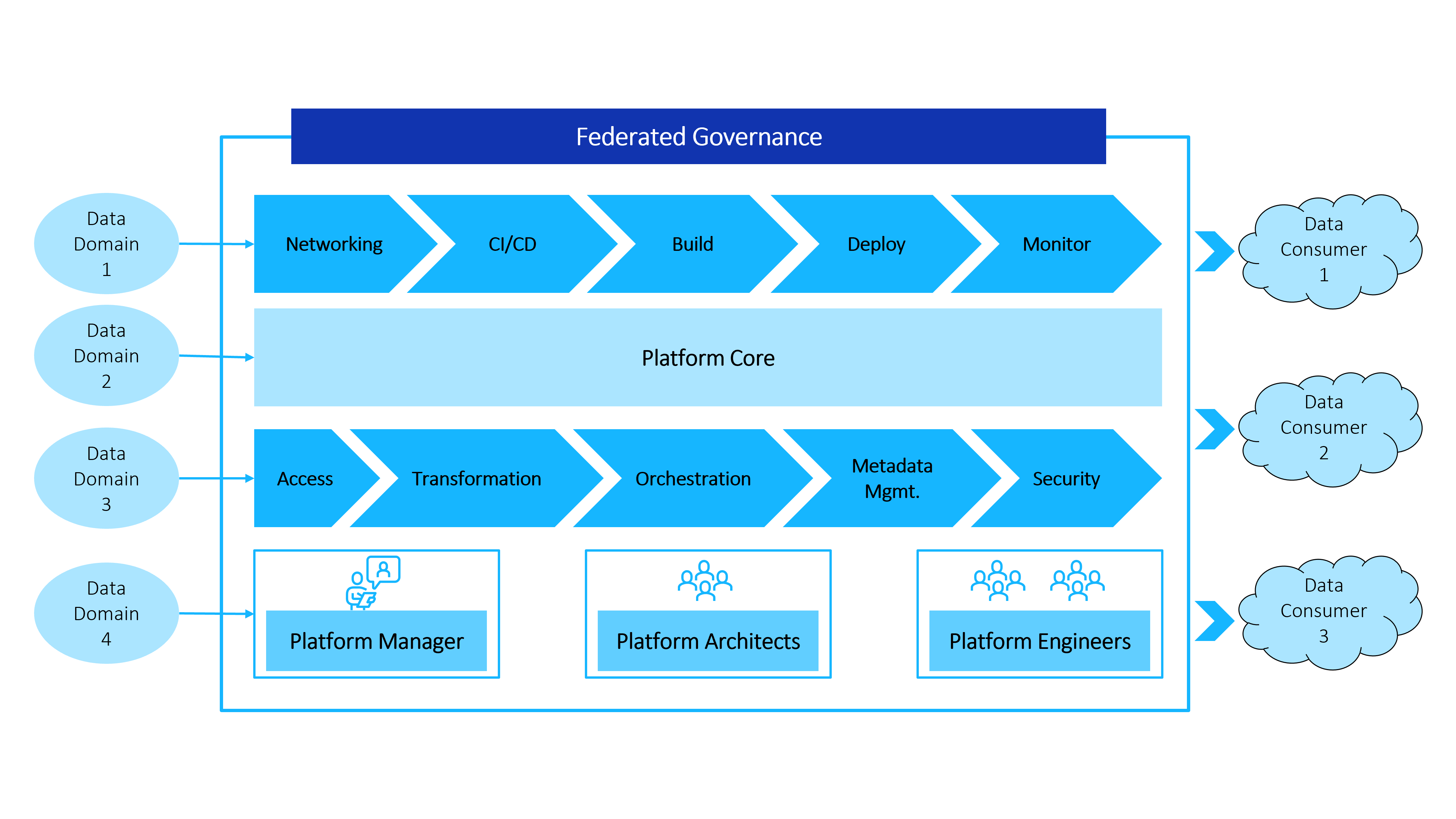
Self-serve data infrastructure as a platform: Domain teams can create, transform, and consume data products autonomously.
Federated governance: Mandated universal standards to enable smooth interoperability and flow of data.
The Data Mesh brings many benefits to the table.
Flexibility and Choice – Since its architecture is domain driven and distributed, you have the flexibility to choose vendors and technologies that work best for you, without getting locked onto one platform.
Greater agility, seamless collaboration, shorter project times - Since domain teams own their data, they can operate independently, making them more agile and responsive. At the same time, since the teams are cross-functional, collaboration becomes simpler and more efficient. Development accelerates and projects go live faster!
Superior quality – Since ownership is vested with domain experts, the quality of the data is always high. Further, by mandating universal protocols and principles, the Data Mesh promotes the delivery of data in standardized formats for easier access.
Quick service: Data producers and data users interact based on pre-determined SLAs, enabling much faster data delivery. All data management needs such as storage, logging, identity management, and such, which slow the process down, are handled by the Data Mesh’s inbuilt capabilities.
Scalability: Being distributed in structure the Data Mesh is also eminently scalable with minimal disruption.
So, should your company upgrade to a Data Mesh?
A Data Mesh certainly sounds like a panacea for all data ills but, like all technology solutions, it must be opted for after due thought and diligence. Keeping the following factors in mind will help you make a better-informed decision about whether your organization needs to upgrade to a data mesh.
Duplication of data: Repurposing data to serve another domain’s needs may lead to data duplication. This can lead to higher storage requirements as well as increased data management costs.
Quality Avoidance: The availability of multiple data products and pipelines may lead to non-compliance with governance standards. Therefore, these principles will need to be clearly articulated and compliance enforced through appropriate measures at the domain level.
Change management efforts: Deploying data mesh architecture and decentralized data operations will entail organization-wide change management efforts. You will need to plan to allow for business disruptions and to ensure that critical operations continue.
Choosing future-proof technologies: Teams will have to think long-term when selecting technologies that will be standardized across the company, to ensure easier future upgradation with minimal disruption.
Cross-domain analytics: Reporting becomes decentralized as well, and a separate organization-wide model may need to be defined to consolidate diverse data products into one report.
Bhagaban Khatai
Data Transformation Leader, ITC Infotech
A Technology evangelist with 17+ years of experience as a Global SME for Data and Analytics. Focused on strategic problem solving, change management, and successful execution to achieve the planned results. Professional growth fueled by Strategic Thinking, Solution-Oriented Approach, Trusted Partner, Consulting, and Driving Growth and tangible impact.
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
ITC Infotech is a leading global technology services and solutions provider, led by Business and Technology Consulting. ITC Infotech provides business-friendly solutions to help clients succeed and be future-ready, by seamlessly bringing together digital expertise, strong industry specific alliances and the unique ability to leverage deep domain expertise from ITC Group businesses. The company provides technology solutions and services to enterprises across industries such as Banking & Financial Services, Healthcare, Manufacturing, Consumer Goods, Travel and Hospitality, through a combination of traditional and newer business models, as a long-term sustainable partner. ITC Infotech is a wholly owned subsidiary of ITC Ltd. ITC is one of India’s leading private sector companies and a diversified conglomerate with businesses spanning Consumer Goods, Hotels, Paperboards and Packaging, Agri Business and Information Technology. For more information, please visit: http://www.itcinfotech.com/
The 3 AM coffee runs, endless sprint cycles, and that perpetual "just one more feature" mindset – sound familiar? If you're part of India's tech ecosystem, you've probably witnessed (or lived through) this reality more times than you'd like to admit…
Most enterprises can track resource schedules, time logs, and project status, yet real-time insight into how those decisions influence profitability remains elusive. This disconnect forces teams to juggle separate systems for project tracking,…
Think of a scenario where an AI system analyzes a client’s frustrated tone in a support call. Upon cross-referencing their usage data, the system not only alerts the account manager but also equips them with de-escalation strategies. Once a distant…
Data extraction has long been a fundamental aspect of business operations across industries. Whether it's for record keeping, financial transactions, compliance documentation, or customer onboarding, the ability to accurately extract and process…
The Patchwork Problem
India’s fragmented legal and regulatory environment poses a serious challenge to data center development. The absence of uniform definitions, exponential state-specific approval processes, and ineffective single-window…
The sun had barely risen when Officer Ray received his fifth call of the day.
A street fight reported in Sector 18.
A cow stuck in an open drain near the railway line.
Waterlogging on a school route, blocking buses.
A burst pipe triggering a…