The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
Simultaneous Localization and Mapping (SLAM) has always been a hot topic in robotics and related fields. Exceptionally reliable technologies and solutions have evolved over the decades of research and development, yet it is still considered to be an unsolved problem.
There are many reasons, including the ever-growing applications of robotics that evolved from simple manipulators to complex robotics applications including self-driving cars. And for almost all those applications, a part of the problem to be solved is the same: The questions of where the robot is, what do my surroundings look like and how can I move around?
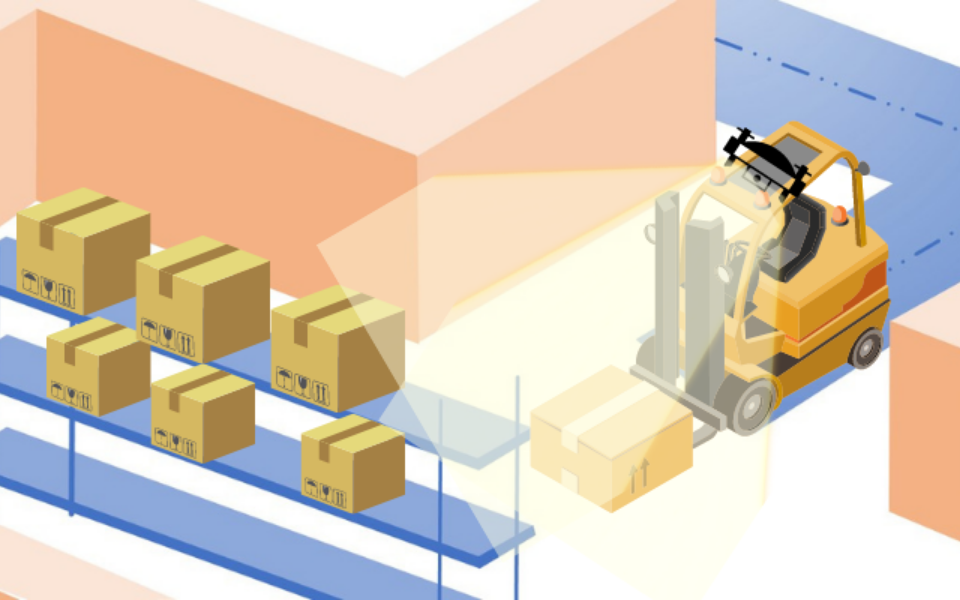
SLAM tries to answer these questions, especially in the case of Autonomous Mobile Robots (AMRs). Over the years, many methods have been used to implement SLAM by using various sensors including 3D LiDAR’s, 2D Lidars, Radar, Stereo/RGB-D/Monocular Cameras etc. SLAM is often implemented with multiple sensors to reduce errors and increase accuracy. Each method that uses the above-mentioned techniques has its own advantages and disadvantages and a universal solution is not yet fully developed that can solve the issues in SLAM.
2. LiDAR SLAM v/s Visual SLAM
The two trending topics in SLAM are now Lidar based SLAM and Vision (Camera) based SLAM. The Lidar SLAM employs 2D or 3D Lidars to perform the Mapping and Localization of the robot while the Vison based / Visual SLAM uses cameras to achieve the same.
LiDAR SLAM uses 2D or 3D LiDAR sensors to make the map and localize within it. Generally, 2D Lidar is used for indoor applications while 3D Lidar is used for outdoor applications. Being a more mature sensor technology LiDAR SLAM comes with its own advantages of being the most accurate SLAM Technology, thanks to the active sensor used and the sensor fusion algorithms.
On the other hand, Visual SLAM uses vision-based sensors: Monocular, Stereo and RGB-D Cameras. These techniques find application in various robotics applications including both indoor and outdoor robotics use cases.
While LiDAR SLAM is more reliable, precise and prone to fewer errors, it has its drawbacks:
It demands a lot more compute power due to the type of data it handles
The infrastructure cost for the LiDAR and the associated hardware is comparatively expensive at this point of time
Other perception tasks including object detection and sign-board detection are much more complex
Lack of semantic information
This is where Visual SLAM algorithms get the spotlight. With cheaper hardware requirements and constantly improving algorithms, Visual SLAM is gaining more popularity and attention. The less compute requirement and the fact that the camera used for Visual SLAM can be used for other perception activities makes it a tempting choice in making autonomous robots with slow to medium speeds. And even the self-driving industry is utilizing the possibilities and applications of vision-based SLAM.
3. Visual SLAM (VSLAM) : Is it the Way Forward?
Vision sensors can exact more and viable information both in color and per pixel about location than any other sensor. Vision sensors are favored because people and animals seem to be navigating effectively in complicated locations using vision as a primary sensor. Various researchers have focussed on Visual Simultaneous Localization and Mapping (VSLAM) with exceptional results; however, many challenges still exist.
In this blog series, we will be exploring the possibilities of Visual SLAM in robotics, by evaluating different V-SLAM techniques. We will discuss the possibilities of complex applications in terms of reliability, accuracy and efficiency of those techniques and algorithms. You will also find a bonus section (with a demo video) on one of the hottest Visual SLAM techniques, ORB SLAM algorithm.
4. Types of VSLAM techniques
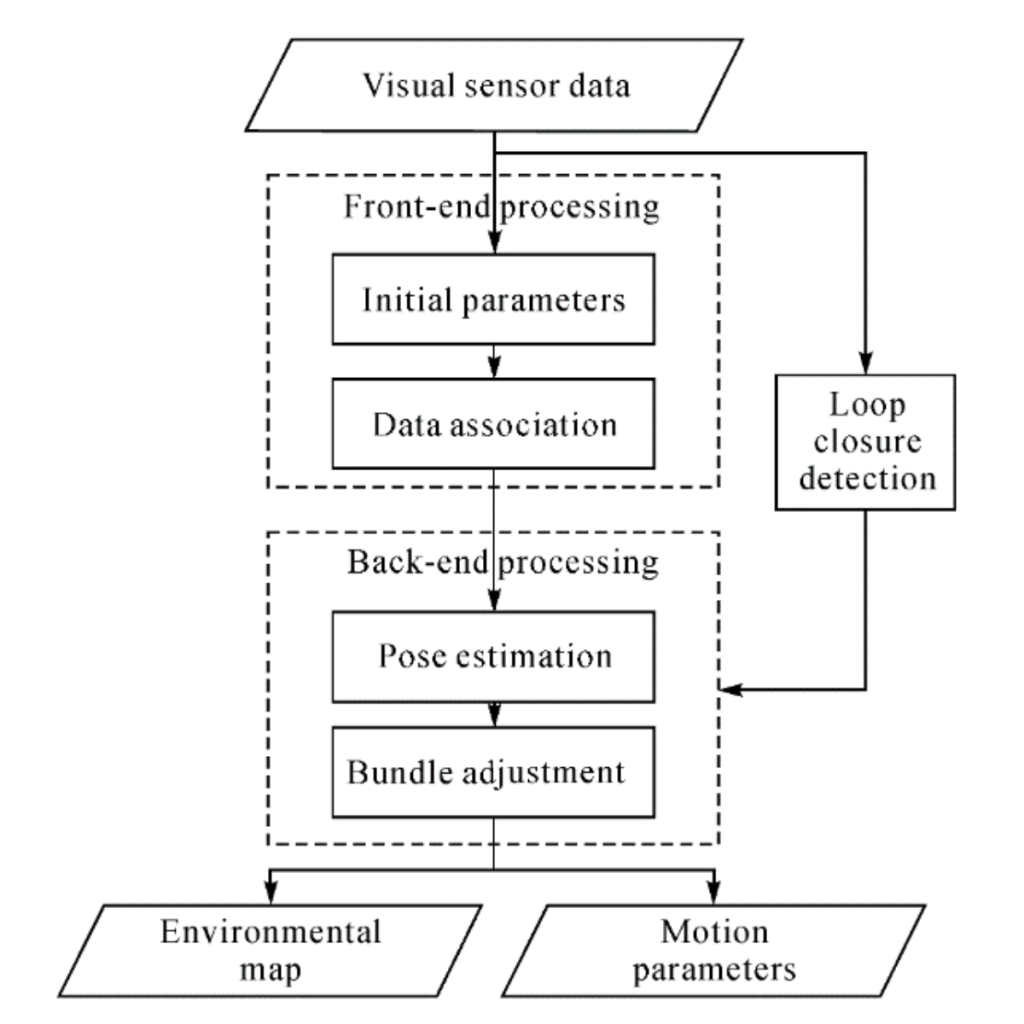
Visual sensors have been the main research direction for SLAM solutions because they are inexpensive, capable of collecting a large amount of information, and offer a large measurement range. The principle of VSLAM is simple, the objective is to estimate sequentially the camera motions depending on the perceived movements of pixels in the image sequence. This can be done in different ways. One approach is to detect and track some important points in the image; this is what we call Feature-based VSLAM. Another one is to use the entire image without extracting features; such an approach is called Direct SLAM. Of course, other SLAM solutions also exist using different cameras such as RGB-D or Time-of-Flight (ToF) cameras (which provide not only an image, but also the depth of the scene), or event cameras (detecting only changes in the image).
Fig: Flowchart of a typical VSLAM System
4.1 Feature-based SLAM
Feature-based SLAM can be divided again into two sub-families: filter-based, and Bundle Adjustment-based (BA) methods.
While landmarks such as buildings and signposts are easily identified by humans, it is much easier for machines to identify and match low level features such as corners, edges, and blobs. More sophisticated feature definitions, together with detection algorithms and descriptors (a distinct feature representation) have been invented, such as Scale-invariant Feature Transform (SIFT), Speeded Up Robust Features (SURF) and Oriented FAST and Rotated BRIEF (ORB). These features are designed to be robust to translation, rotation, variations in scale, viewpoint, lighting, etc. A limitation to the feature-based approach is that, once the features are extracted, all other information contained in the image is disregarded. This could be problematic when feature matching alone cannot offer robust reconstruction, e.g., in environments with too many or very few salient features, or with repetitive textures
4.2 Direct SLAM
In contrast to feature-based methods, direct methods directly use the image without any feature detectors and descriptors. Such feature-less approaches use photometric consistency to register two successive images (for feature-based approaches, the registration is based on the geometric positions of feature points). In this category, the most known methods are DTAM, LSD-SLAM, SVO, or DSO. Finally, with the development of deep learning, some SLAM applications have emerged to imitate the previously proposed approaches. Such research has generated semi-dense maps representing the environment, but direct SLAM approaches are time consuming and often require GPU-based processing.
4.3. RGB-D SLAM
The structured light-based RGB-D camera sensors recently became inexpensive and small. Such cameras can provide 3D information in real-time but are used for indoor navigation as the range is inferior to four or five meters and the technology is extremely sensitive to sunlight. One can refer to RGB-D VSLAM approaches.
4.4 Event Camera SLAM
An event camera is a bio-inspired imaging sensor that can provide an “infinite” frame rate by detecting the visual “events,” i.e., the variations in the image. Such sensors have been recently used for V-SLAM. Nevertheless, this technology is not mature enough to be able to conclude about its performance for SLAM applications.
5. Popular VSLAM Algorithms
5.1 RTAB-Map SLAM
RTAB-Map stands for Real-Time Appearance Based Mapping. It has been distributed as an open-source library since 2013. RTAB-Map started as an appearance-based loop closure detection approach with memory management (shown in below figure) to deal with the large-scale and long-term online operation. It then grew to implement Simultaneous Localization and Mapping (SLAM) on various robots and mobile platforms. RTAB-Map supports both visual and LiDAR SLAM, providing in one package a tool that allows users to implement and compare a variety of 3D and 2D solutions for a wide range of applications with different robots and sensors. It uses depth images with RGB images to construct maps. The graph is created here, where each node contains RGB and depth images with corresponding odometry pose. The links represent the transformations between nodes. When the graph is updated, RTAB-Map compares the new image with all previous ones in the graph to find a loop closure. When a loop closure is found, graph optimization is done to correct the poses in the graph. For each node in the graph, we generate a point cloud from the RGB and depth images. This point cloud is transformed using the pose in the node. The 3D map is then created.
Where RTAB map can be used: 3D reconstruction
RTAB map is more computationally intensive. So, optimizing it for a small-scale system would affect performance. Also, it can run only on RGB-D/ Stereo cameras and Lidars
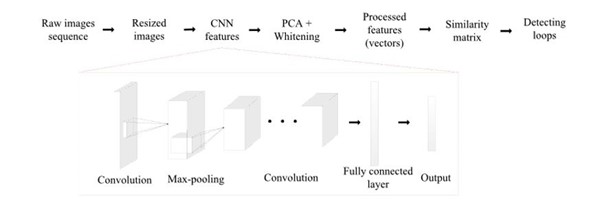
5.2 Deep Learning in VSLAM
Geometry-based and Deep learning-based visual odometry paradigms.
The geometry-based visual odometry computes the camera pose from the image by extracting and matching feature points.
The deep learning-based visual odometry can estimate the camera pose directly from the data. For supervised visual odometry, it requires external ground truth as the supervision signal, which is usually expensive. In contrast, the unsupervised visual odometry uses its output as supervision signal. Besides, the local optimization module is optional for deep learning-based visual odometry.
Fig. A Sample deep-learning based SLAM system architecture.
5.3 ORB-SLAM
ORB-SLAM is a real-time SLAM library for monocular, stereo and RGB-D cameras that computes the camera trajectory and a sparse 3D reconstruction. It can detect loops and re-localize the camera in real time. The system works in real-time on standard CPUs in a wide variety of environments from small hand-held indoor sequences, to drones in industrial environments and cars driving around a city. The back end based on bundle adjustment with monocular and stereo observations allows for accurate trajectory estimation with metric scale. The system includes a lightweight localization mode that leverages visual odometry tracks for unmapped regions and matches map points that allow for zero-drift localization. The main functionalities of ORB SLAM are feature tracking, mapping, loop closure and localization.
Where ORB can be used:
Visual Odometry and Localization for Robots (indoor and outdoor)
The recent update of ORB SLAM 3 is a big leap and shows great possibilities such as:
ORB-SLAM3 is the first system able to perform visual, visual-inertial and multi-map SLAM with monocular, stereo and RGB-D cameras, using pinhole and fisheye lens models.
It is a feature-based tightly integrated visual-inertial SLAM system that fully relies on Maximum-aPosteriori (MAP) estimation, even during the IMU initialization phase. It is a system that operates robustly in real time, in small and large, indoor and outdoor environments, and is two to ten times more accurate than previous approaches.
ORB-SLAM3 is the first system able to reuse in all the algorithm stages all previous information.
It has a multiple map system that relies on a new place recognition method with improved recall. ORB-SLAM3 can survive long periods of poor visual information: when it gets lost, it starts a new map that will be seamlessly merged with previous maps when revisiting mapped areas.
It has a multiple map system that relies on a new place recognition method with improved recall. ORB-SLAM3 can survive long periods of poor visual information: when it gets lost, it starts a new map that will be seamlessly merged with previous maps when revisiting mapped areas.
Conclusion
With the advancements in computer vision and processing capabilities, VSLAM algorithms are on the path to greatness. Even though the environmental and optical conditions can affect performance, latest techniques and methods including sensor fusion and deep learning are showing light to the possibility of robots that need only ‘eyes’ to move around.
ORB SLAM 3 is one of the most popular algorithms among VSLAM techniques. And in the next part of the blog, we will be diving deep into the ORB SLAM algorithm and its usability and capabilities.
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
In today’s rapidly evolving world, the importance of sustainable development cannot be overstated. The United Nations’ Sustainable Development Goals (SDGs) provide a comprehensive framework to address global challenges such as poverty, inequality,…
In the rapidly evolving world of healthcare, having a cutting-edge app isn’t just a luxury—it’s a necessity. As we look to the future, the question every healthcare app developer should be asking is: "Is my app prepared for what’s coming next?" With…
Methodology
Inrate’s rating methodology has been carefully developed to reveal real impact based on what a company does, not just what it says. It aligns seamlessly with the expectations of leading regulations such as the EU Taxonomy, …
In the dynamic world of sustainable investing, ESG Screening Solutions have become essential for investors aiming to align their portfolios with their ethical and sustainability values. These solutions provide a comprehensive framework for…
According to Experian, 95% of business leaders report a negative impact on their business due to poor data quality. It shows the importance of data validation as a critical step to ensure a smooth data workflow. Any inconsistencies in data at the…
In the dynamic world of investing, Portfolio Analysis & Reporting has become a cornerstone for investors seeking to optimize their strategies and ensure sustainable growth. But what exactly does this entail, and how can it…