The use of this site and the content contained therein is governed by the Terms of Use. When you use this site you acknowledge that you have read the Terms of Use and that you accept and will be bound by the terms hereof and such terms as may be modified from time to time.
All text, graphics, audio, design and other works on the site are the copyrighted works of nasscom unless otherwise indicated. All rights reserved.
Content on the site is for personal use only and may be downloaded provided the material is kept intact and there is no violation of the copyrights, trademarks, and other proprietary rights. Any alteration of the material or use of the material contained in the site for any other purpose is a violation of the copyright of nasscom and / or its affiliates or associates or of its third-party information providers. This material cannot be copied, reproduced, republished, uploaded, posted, transmitted or distributed in any way for non-personal use without obtaining the prior permission from nasscom.
The nasscom Members login is for the reference of only registered nasscom Member Companies.
nasscom reserves the right to modify the terms of use of any service without any liability. nasscom reserves the right to take all measures necessary to prevent access to any service or termination of service if the terms of use are not complied with or are contravened or there is any violation of copyright, trademark or other proprietary right.
From time to time nasscom may supplement these terms of use with additional terms pertaining to specific content (additional terms). Such additional terms are hereby incorporated by reference into these Terms of Use.
Disclaimer
The Company information provided on the nasscom web site is as per data collected by companies. nasscom is not liable on the authenticity of such data.
nasscom has exercised due diligence in checking the correctness and authenticity of the information contained in the site, but nasscom or any of its affiliates or associates or employees shall not be in any way responsible for any loss or damage that may arise to any person from any inadvertent error in the information contained in this site. The information from or through this site is provided "as is" and all warranties express or implied of any kind, regarding any matter pertaining to any service or channel, including without limitation the implied warranties of merchantability, fitness for a particular purpose, and non-infringement are disclaimed. nasscom and its affiliates and associates shall not be liable, at any time, for any failure of performance, error, omission, interruption, deletion, defect, delay in operation or transmission, computer virus, communications line failure, theft or destruction or unauthorised access to, alteration of, or use of information contained on the site. No representations, warranties or guarantees whatsoever are made as to the accuracy, adequacy, reliability, completeness, suitability or applicability of the information to a particular situation.
nasscom or its affiliates or associates or its employees do not provide any judgments or warranty in respect of the authenticity or correctness of the content of other services or sites to which links are provided. A link to another service or site is not an endorsement of any products or services on such site or the site.
The content provided is for information purposes alone and does not substitute for specific advice whether investment, legal, taxation or otherwise. nasscom disclaims all liability for damages caused by use of content on the site.
All responsibility and liability for any damages caused by downloading of any data is disclaimed.
nasscom reserves the right to modify, suspend / cancel, or discontinue any or all sections, or service at any time without notice.
For any grievances under the Information Technology Act 2000, please get in touch with Grievance Officer, Mr. Anirban Mandal at data-query@nasscom.in.
Data annotation is the process of adding tags or labels to raw data such as images, videos, text, and audio. These tags form a representation of what class of objects the data belongs to and helps a machine learning model learn to identify that particular class of objects when encountered in data without a tag. Data annotation (also known as data labeling) plays a very important role in ML (Machine Learning) and AI-based projects.
Different kinds of input data call for different types of labeling approaches. For example, for speech labeling, samples are ‘cut’ into segments that might represent noise or silence or the temporal boundaries of specific spoken keywords. For text labeling for (say) an NLP (Natural Language Processing) application, a specific word or phrase segment would be labelled and segregated into different classes. For a gesture control application, numerical data (eg. X, Y, Z axis data from an accelerometer or a gyroscope) would be labelled in their frequency domain to identify specific signatures associated with an action in 3D space.
In this article, we consider still image and moving video as our input data. We describe various kinds of image label types, standard tools, custom extensions for improving labeling efficiency, integration with standard AI project infrastructure and well as different labeling workflows.
2. Types Of Image Data Annotations
Various types of data annotation methods are adopted based on the specific detection or classification problem that is being addressed. Various ML and DL (Deep Learning) algorithms require annotations to be in different formats to allow object features to be recognized and extracted efficiently during the inference process. In order to get the best possible results, it is crucial to use the proper type of annotation.
Some of the common image annotation types are the following:
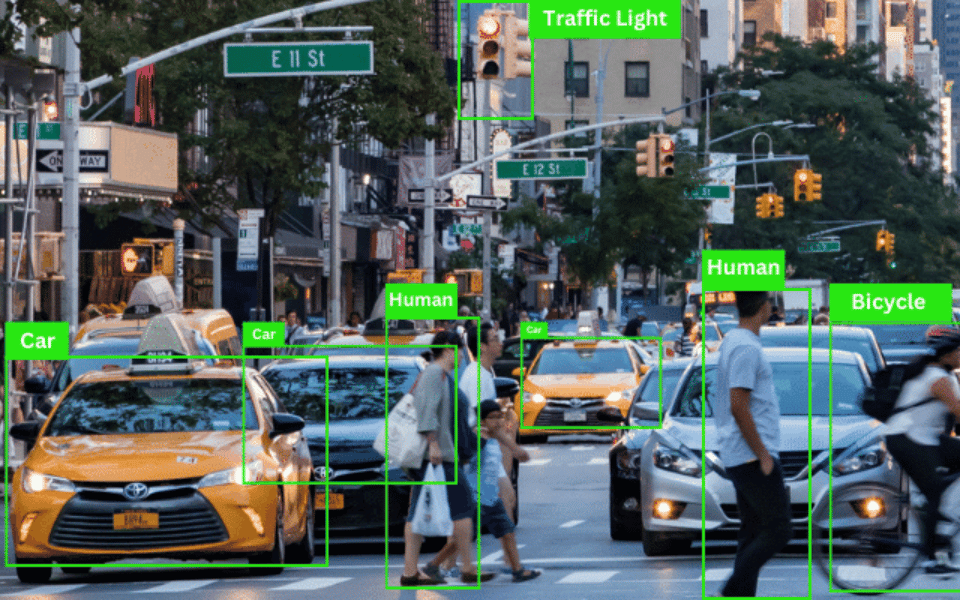
2.1 Bounding Boxes
Bounding boxes are generally used as labels for detector class of AI applications, allowing high accuracy object recognition and perception models to be built. From the ubiquitous cat/dog localization in an image to self-driving vehicles, these relatively simple class of annotations are highly relevant in many practical applications.
Polygon annotation is a multipoint annotation technique employed to draw shapes, curves and various angles. They mark pixel level category annotations in an image.
Key Points are used to detect small objects and shape variations by creating dots across the image. This helps with detecting and labeling facial / skeletal features, expressions, emotions, human body parts, poses and landmarks.
Lines and splines are used to mark the boundaries of a region of interest within an image that contains the target object. This is often used when regions of interest containing target objects are too thin or too small for bounding boxes.
A vast variety of annotation tools are used by the industry – ranging from open source to proprietary. Listed below are some of the popular image annotation tools:
LabelImg
LabelImg is a graphical image annotation tool allowing labeling of object bounding boxes in images.
Labelme is an open-source annotation tool. It was written in python to support manual polygonal annotation of objects for classification and segmentation. Labelme allows the creation of various shapes including polygon, circles, rectangles, lines, line strips, points etc.
Makesense is a free-to-use online tool for labeling images. It is used for small computer vision / deep learning projects. Generated labels can be downloaded in multiple formats.
CVAT (Computer Vison Annotation Tool) is a popular web based open-source image and video annotation tool developed by Intel. CVAT is used for labeling data for image classification, object detection, image segmentation. CVAT offers different types of shapes for annotation such as rectangle, polygon, points, ellipse, polyline, cuboid. It supports multiple annotation formats: label VOC XML, label COCO JSON, label YOLO annotations etc.
SuperAnnotate is an end-to-end platform to annotate image, video and text. This advanced tool offers different types of shapes for annotation such as bounding box, polygon/polyline, ellipse, keypoint, cuboid. This tool enables the annotation of images and videos with high accuracy.
Even though a plethora of highly capable open-source annotation tools exist, most of them suffer from lack of specific features that are practically required for the execution of large and complex AI projects. At Ignitarium, we have developed custom extensions to the above tools to incorporate key features such as the following:
Client-server based multiple labeler support wherein single images or batches of images can be served (with workflow tracking) to remotely located, individual annotation engineers in a team
Support for contour hierarchies
Improved support for precise semantic labelling
Enforcement of parent-child relationships
Ability to add custom image label tags
Better integration into source code repositories (eg. Git)
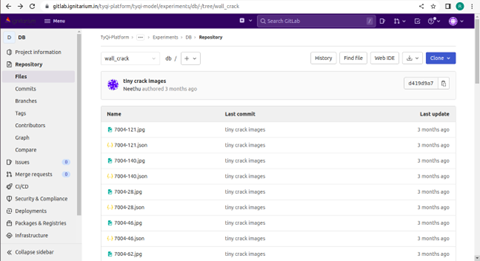
Fig. 5: Integration of enhanced labelling tool with Gitlab
5. Image Labeling Workflows
AI teams employ various strategies to efficiently deal with the vast amount of data that needs to be labelled and managed as part of complex projects.
5.1 Manual Labeling
The tried and tested method employed by most teams is to perform manual dataset labeling leveraging natural intelligence of humans in recognizing patterns even within poor quality images.
Internal Labeling
This is when experts within the company label datasets. It is also known as in-house labelling. Labelers within an AI team usually know what is specifically needed for a particular type of model. This is usually the highest quality labelling approach with more accurate annotations. Data resides on systems that adhere to a company’s IT policies and hence the risk of data leakage is minimal.
External Labeling
In this method, also known as out-sourced/crowd-sourced labeling, annotation tasks are given to external labelers or freelance workforce outside the company. The difference between crowd-sourced and out-sourced labeling is that crowd-based labeling assigns tasks to a group of unorganized workers, whereas outsourcing involves an organized workforce – usually a company that specifically focuses on data annotation as a business.
At Ignitarium, our strategy has been largely the following:
For PoC level projects or where complex, high precision annotations are called for, we use our internal expert-level labeling team
For high data volume projects, our expert annotators will generate sample labels for complex scenarios, provide these as reference to the workforce of a trusted annotation partner company and then participate in the review of critical labels and / or randomly selected labels, as a quality assurance measure
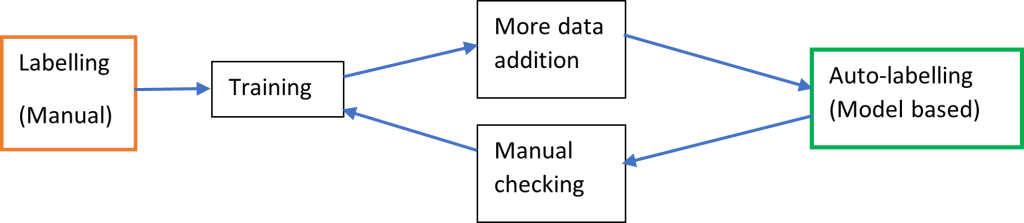
5.2 Human-in-the-loop training and Auto-Labelling
The Human-in-the-loop workflow judiciously blends both human and machine intelligence to generate AI models faster. Generally, the process starts with a human labeling the data and then this being used to train a model. As the model matures, this model is used to generate more labels automatically. These generated labels are inspected, validated, or corrected by humans, thus iteratively increasing the accuracy and volume of the labels as well as the quality of the model used for auto-labeling. The workflow has to be carefully implemented with the AI model team and the annotation team collaborating closely to achieve faster convergence.
Fig. 6: Human-in-the-loop workflow
At Ignitarium, we leverage our rich set of model libraries to quickly incorporate model-based auto-labeling into the majority of our AI projects.
6. Application Examples
We have executed 100+ still image and video-based AI projects across a host of application domains using open source and custom-enhanced labeling tools. A few sample use cases from our TYQ-i(TM): Deep Learning based Defect Detection Platform are shown below:
Fig 7: Labelling of wind turbine blades and tower, Source
Figure 7 shows the wind turbine blade contours and the super-structure being labelled. This will be used as the first level (parent) hierarchy for subsequent labeling of defects (child) within the body of the blade or the super-structure.
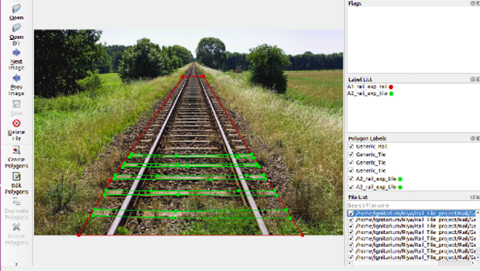
Fig 8: Labelling of rail-track and ties
Figure 8 shows our customized labeling tool being used to annotate rail tracks and wooden ties. Next level labels will include finer artefacts like cracks, plates, spikes etc.
7. Challenges In Data Annotation
The most common challenges in data annotation are:
Time consuming: Manual data labeling is highly time-consuming and can prove to be very expensive based on the data volume.
Chances of human error: Quality refers to how consistently accurate an entire dataset is. The problem of incorrect data labels affects the quality of data and leads to inaccurate models.
Human bias: The interpretation of what an artifact (and eventually the corresponding label) actually is, can vary between different labelers. Timely reviews by expert labelers and constant sync-up with the model teams can reduce this bias.
8. Conclusion
It can be safely said that the fate of an AI / ML project is dependent heavily on the quality of annotated data. The choice of annotation tool, advanced multi-labeler collaboration infrastructure, a smart mix of auto-labeling & manual annotation workflows and a small expert labeler oversight team are usually the difference between a highly quality AI model or an average one.
That the contents of third-party articles/blogs published here on the website, and the interpretation of all information in the article/blogs such as data, maps, numbers, opinions etc. displayed in the article/blogs and views or the opinions expressed within the content are solely of the author's; and do not reflect the opinions and beliefs of NASSCOM or its affiliates in any manner. NASSCOM does not take any liability w.r.t. content in any manner and will not be liable in any manner whatsoever for any kind of liability arising out of any act, error or omission. The contents of third-party article/blogs published, are provided solely as convenience; and the presence of these articles/blogs should not, under any circumstances, be considered as an endorsement of the contents by NASSCOM in any manner; and if you chose to access these articles/blogs , you do so at your own risk.
Building reliable AI chatbots is harder than it looks. Developers know the pain: you create a promising conversational AI, but how can you be sure it's actually giving accurate, trustworthy responses? Enter ContextCheck – the tool we developed to…
Tata Technologies has cracked the code on generative AI. Recently, the company told AIM that it has built a solution (design studio for automotive selling) using Llama 2 and Stable Diffusion 3 which will…
Ever find yourself drowning in an ocean of notifications? Your phone buzzing every few minutes with news updates, social media pings, and app alerts until you are ready to throw it out the window? You are not alone! This is exactly why the AI-…
Just as ChatGPT and Meta AI are becoming integral parts of our daily lives, the health sector too is witnessing its impact. While some might argue that AI can never replace the human touch, it’s undeniable that its influence is growing.
From…
As a Senior Data Scientist, I’ve seen directly how data science can transform businesses. Whether you’re running a small startup or managing a large corporation, data science can give you the tools and insights needed to make smarter decisions,…
Electric motorcycles have gained significant attention in the market and transportation industry as an advanced innovation since they are quieter, cleaner, and more efficient than ICE vehicles. Nevertheless, some issues, like a small range,…