Introduction
As businesses in virtually every industry move to algorithmic decision making, the subject of fairness in these decisions are often completely ignored or left as an afterthought. In the emerging data economy where innovation and competitive strategy will be driven by the “data advantage” and what companies can do with data, it would be irresponsible not to consider the implications that these algorithms can have on individuals and society.
The more data you feed to pattern recognition algorithms the better it is able to discriminate between groups [1] and are rewarded for doing so. Although these so called accurate predictive algorithms could create short term value, the bias produced in their results could potentially cause unwanted harm to some groups and prove to be a huge risk to organizations.
However, companies can adopt key strategies from the onset to combat these problems to realize the true potential that lies in AI and automated decision making.
Data Science impacts lives
Al can consume huge amounts of data, make faster and more consistent decisions than humans, leading to massive gains in productivity and efficiency. However, the “move fast and break things” philosophy adopted by technology companies in the last decade has proved to be ill-fitting to AI applications, as is extensively documented by data journalists and independent research institutions. ProPublica, a nonprofit organization working in investigative journalism, showed in the Pulitzer prize finalist series “Machine Bias” how an algorithm designed to predict future criminals is biased against certain ethnic groups [2] and in another, car insurance companies are shown to charge more premium to minority neighbourhoods than white areas with the same risk [3]. These results may not always be the result of disparage treatment, for AI algorithms that are optimized to identify high value customer would accordingly discriminate against low income groups. Removing dimensions that identify historically discriminated groups such as gender, race or disability does not always work since the existing bias in the data can still help find good proxies to identify these groups.
The pervasive use of surveillance cameras and facial recognition technology is also concerning. In the city of Zhengzhou, Chinese authorities are using facial recognition to keep tabs on the Uighurs, a Muslim minority group. Developments in affect recognition, subclass of facial recognition that claims to detect things such as personality, inner feelings, mental health, and “worker engagement” based on images or video of faces, when linked to hiring or policy decisions threatens to bring back physiognomic ideas from the Nazi era. [4]
Understanding the effects of these systems can sound complex and esoteric but systematic efforts by experts, who understand AI and regulations, and thorough analysis of each part of the Data Science process can help provide a clearer picture of the expected outcomes before organizations can start deploying these models.
The “right to explanation” and its implications
In April 2016, the European Parliament adopted a set of comprehensive regulations for the collection, storage and use of personal information, the General Data Protection Regulation (GDPR) [5], which would go into effect from May 2018.
Article 22 (Automated individual decision making, including profiling) and Article 13-15 are of particular interest to organizations looking to venture into AI or that have already deployed AI models as these provisions could potentially cause an overhaul of popular techniques used in recommendation systems, credit and insurance risk assessments,
computational advertising, and social networks.
Article 22 specifically addresses discrimination from profiling that makes use of sensitive data. As previously discussed, removal of these sensitive information that code for race, finances, or any of the other categories of sensitive information referred to in Article 9 does not ensure compliance since other correlated variables can form proxies for these “special categories of personal data”.
Article 22 also prohibits any “decision based solely on automated processing, including profiling” which “significantly affects” a data subject. This requires companies to manually review significant algorithmic decisions which would increase labour costs.
Article 13-15 specifies that data subjects must have the right to access the data collected and be notified about it. Additionally, companies must provide explanations for individual algorithmic decisions that affect the data subjects.
Standard Machine learning algorithms aim to maximise accuracy and other similar metrics by separating groups (classification) through finding association and correlations in the data with no concern for causal inference beyond interpretation of explainer variance. On the other hand, the increasing use of complex models such as Deep Neural networks and ensembles create highly accurate black box systems that are often hard to interpret even by human experts.
Although these apparent challenges impose restrictions and increase complexities on organizations in AI adoptions, they also provide opportunities for their Data Science teams to integrate fair and ethical practices in their algorithm design at the outset.
Privacy in the age of Big Data
Mobile phones, IOT home applications and other information sensing devices are able to generate large volumes of data that businesses can leverage to derive insights about its customers. However, care must be taken while handling personal data so that individual privacy is maintained. A privacy preserving analysis ideally should learn the same thing about the population when one person is replaced by another random member of the population. This prevents any harm that can happen to an individual by being in the database, or choosing to be in the database.
Anonymization or “de-identification” of data often does not generate the results we expect. One of the popular methods that provide the strongest mathematical guarantee is called Differential Privacy[15]. In 2007, Netflix released a large collection of anonymized user data as part of a competition to improve its recommendations. However, researchers at the University of Texas at Austin were able to de-anonymize the data by cross referencing the Netflix data with the public reviews dataset from IMDB.
Differential Privacy is one of the most effective privacy preserving mechanism for big data that is able generate knowledge about a group while learning as little as possible about any particular individual. Through noise mechanisms and other probabilistic techniques, it is able to guarantee an output that hardly changes when a single individual joins or leaves a dataset. This process provides plausible deniability of individual results.
Systematic bias in data and society
Bias in data propagates to model decisions.
Inherent prejudice or even underrepresented samples in the data can cause AI models to make biased decisions against certain groups, as detailed by the ProPublica series “Machine Bias”[2][3].
Big data, or large training datasets (often crowdsourced), although promises to be neutral, contains the same inequality, exclusion or other traces of discrimination as does the society it is collected from.
The Flickr30K dataset [7] is a collection of over 30,000 images with 5 crowdsourced descriptions each. Untested assumptions on the validity of these description can cause unwarranted inferences.

The image above for example have the captions - A worker is being scolded by her boss in a stern lecture; A hot, blond girl getting criticized by her boss. [7]
The ImageNet dataset [8] containing approximately 1.2 million image
thumbnails and URLs from 1000 categories forms the backbone of most image classification tasks and open source models in the industry.
For the 14 million images in the fall 2011 release of the ImageNet data set, the geo-diversity is dominated by a small number of countries.
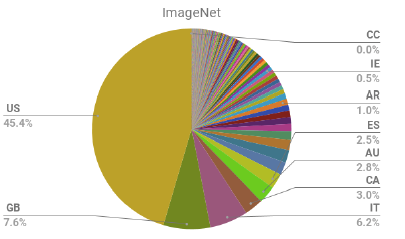
Fraction of Open Images and ImageNet images from each country [9]
These inherent biases in datasets, although produce confident predictions on majority groups, can be much more uncertain about the others. Researchers have shown [10] that even state-of-the art AI models are unable to give equitable predictive performance on pedestrians with different skin tones.
Large text corpora can also contain cultural stereotypes and empirical associations. Researchers have shown [11] how pleasant and unpleasant words are more associated with names of certain ethnic groups.
These limitations, while do not invalidate the usefulness of large datasets, raise some key considerations before deploying automated decision making systems without accessing the assumptions inherent in the datasets. Researchers in data ethics have proposed Datasheets for Datasets[12] suggesting the use of thorough documentation of data collection process, recommended usage and other relevant information to ensure trust and accountability before using such datasets.
Lack of diversity in tech companies and research is also another source of bias in algorithms. A study from UNESCO(United Nations Educational, Scientific and Cultural Organization) titled “I’d blush if I could”[16], borrowed from a response from Siri on being called a sexually provocative term. Female voices in digital assistants continue to be portrayed as servile, providing a powerful illustration of gender biases imbibed in technology products.
Fairness
Although discriminatory behavior may not be a deliberate feature in these systems, inherent bias present in the raw data that is processed can propagate bias into their decisions. The increasing influence of these systems on decisions effecting society calls for development of ways to quantify this bias and integrate fairness as a key feature in the decision making process.
The central challenge is to answer how we should quantify bias, and how to define fairness. While we all may have an intuitive understanding of what is fair, conflicting mathematical interpretations are often hard to optimize in practice.
One possible method to enforce fairness is to hide the sensitive data. However, sensitive attributes are often deeply embedded in the data, such as the correlation of race and zip codes. For e.g. a report from Bloomberg showed that neighborhoods with large black populations were less likely to get the Amazon same day delivery service for Prime members. [14]
Several metrics have been suggested that attempt to mathematically represent various competing notions of fairness, each often mutually exclusive in its interpretation of “fairness” and each varying in applicability based on different contexts.
For example, if there are legitimate reason for differences in the rate of positive labels between groups (i.e. base rates) (e.g. incidence of breast cancer by gender), statistical parity between model results for the protected classes would be inappropriate. However, in certain cases the ground truths present in the raw data may be an unfairly biased representation of the population (label bias), and incorrect choice of metrics based on the types of bias present in the data could cause unwanted consequences [13].
Often we will have a tradeoff between accuracy and fairness – and in turn, group fairness and individual fairness. Group fairness requires similar treatment across groups on average while individual fairness requires that similar individuals be treated similarly. While both are desirable, it is mathematically impossible to optimize both at the same time [17].
Here, we would discuss 2 popular fairness metrics and examine their ability to detect unfair bias in predictions by models trained on data that are known to have bias.
1.Disparate Impact: Often also termed as “Statistical Parity” aims to remove disparate impact, which occurs when a selection process has widely different outcomes for different groups, even as it appears to be neutral.
In other words, we may find disparity if the ratio of positive classifications across protected groups is above a specific cutoff e.g. 0.8. In the context of lending, it requires the bank to lend both groups at the same rate.
2. Equal Opportunity: This metric compared True positive rates between protected groups. E.g. in the context of bank loans, Equal opportunity metric requires the bank to lend both groups at the same rate among individuals who can repay their loan.
Although using both these metrics could reduce the optimal level of profits for organizations, careful considerations on the delayed outcomes from these models could also not fully achieve its altruistic purpose[19].
Our recommendation is to use these fairness metrics with outcome simulations, aided by interpretable models and human judgement.
Explainable AI
Although interpretability should be a key constraint in any sound data science process, it is often reduced to a sideshow in many current applications in Big Data and Deep Learning. However, the legal mandates discussed previously makes it imperative for Data Scientists to address the issue of interpretability while developing complex AI models.
The subject of interpretability was largely addresses by business analysts and researchers through the use of linear models although with a tradeoff of a few points in the accuracy scale. However, recently the proliferation of Deep Learning algorithms and their effectiveness in numerous contexts have made organizations and individuals to truly embrace these “black box” models although with lingering concerns over the limited interpretability that they inherently are able to provide.
These developments call for a fresh perspective on improving the explainability of these algorithms to improve their effectiveness in widespread business applications.
Understanding complex Machine Learning models
The techniques discussed in this paper is restricted to explainability of black-box models and non-linear, non-monotonic functions.
Approaches for interpretability of linear models and tree based models has already been extensively discussed, and is well-studied and understood.
Surrogate models
Surrogate models are interpretable models that are trained with the predictions of our “black box” model to gain a global approximation of that model. Popular interpretable models such as linear regression or decision trees that are used for this purpose can be introspected using techniques such as variable coefficients, variable importance, trends, and interactions. These interpretations could possibly provide a window into the internal mechanisms of a complex model.
However, global surrogate interpretations do not come with any mathematical guarantee of validity and thus we often turn to Local Surrogate models which more accurately is able to find local, monotonic regions in a complex model’s decision boundary. We will be discussing the two most popular methods in this category that are model agnostic explainers – LIME and SHAP.
LIME (Local Interpretable Model-agnostic Explanations) [20]
LIME is defined as a novel explanation method that explains individual model predictions from complex black box models by locally approximating it around a given prediction using a white box model.
We first select an instance whose prediction from the black box model is required. Then, the algorithm perturbs the dataset to produce new points in the neighborhood of the original point and trains a weighted, interpretable model on the dataset with the variants. Feature attributions come in the form of interpretable weights from the white box model.
LIME produces easy to understand explanations that could be useful to a layman. It works for tabular data as well as images and text data.
Below is an example of how the ELI5(ExplainLikeIm5) package, using the LIME algorithm, is able to show how a particular legal clause was classified as a TERMINATION clause.

Shapley Additive Explanations – SHAP [21]
Shapley explanations are derived from calculating Shapley values – a method from coalitional game theory – by assigning feature importance for each prediction. This technique [21] [22] uses game theory concepts to determine how much each player(feature) has contributed to the “payout” (our black box prediction) in a collaborative game. The Shapley value is the average of all the marginal contributions to all possible coalitions.
The SHAP framework [22] provides a unified framework of six existing additive feature importance methods and shows that using this class of methods there is a unique solution that is consistent with human intuition.
These XAI(explainable artificial intelligence) methods come with their own problems[23]. Accurate XAI models may not always be completely faithful to the original model.
Some of the pioneers of AI have expressed concerns on how these explanations should be interpreted. Geoffrey Hinton stated, in an interview in 2018, that explaining a decision of a neural network with simple rules would be counterintuitive and regulators insisting on explaining AI models would lead to a “complete disaster”. Peter Norvig argues that having inner access to the model’s internals does not align with its reasoning. Since the decision is made by one system and we train another system to generate explanations, this approach alone would not be a reliable way to monitor the decision making process.
However, continued research into XAI can result in better approaches that outline an explanation and understanding of these black box models to work towards ethical and transparent practices in AI decision making.
Who will solve the problem …
The failures discussed here and many more that have occurred in the last few years warrant the need for an urgent discussion towards policy and regulation around AI.
The pervasive use of AI in business and society has raised serious ethical challenges that governments is no longer able to ignore. Regulations surrounding disruptive technologies such as facial recognition and self-driving cars must be forward looking. In response to the threats of facial recognition and surveillance technology on the public as discussed previously, San Francisco has recently banned use of facial technology by the police and other agencies. However, domains such as healthcare, justice etc. have mature sector specific agenises that must spearhead the need for newer regulations in these areas.
Similar to the EU’s response with the GDPR regulations, The state of California passed the California Consumer Protection, taking effect from Jan 2020, that required companies to take adequate measures on how consumer data is collected , and provides rights to access the data collected as well as block any sale of their data.
We cannot expect technology companies to solve these problem alone when they struggle to address issues of inclusion and diversity in their own organizations. Google formed an AI ethics board in March that it dissolved a week later. Facebook is providing a funding of $7.5 million to partner with the Technical University of Munich, Germany for AI ethics research, but fail to face the UK parliament for its involvement in the Brexit campaign. Companies funding research into the societal impacts on its own systems will not render change unless we see Governments/independent regulatory bodies making sure that technology companies have strong internal accountability structures that can audit AI models independently and provide the public with the accountability and transparency required for widespread adoption.
Conclusion
With the proliferation of AI systems and the rapid pace of research of this area, the promise of AI disrupting business processes and making autonomous decisions seems inevitable.
However, Organizations going through a Digital Transformation and adopting AI in its processes must also understand the risks it introduces in their businesses and the impact it may have on society and individuals. To address the issue at its roots, we need to encourage multidisciplinary discussions with experts from other disciplines such as social science, law, public policy etc. and conduct a transparent and inclusive research effort to guide technology in the right direction.
Deeper understanding of the algorithms, outcome studies, impact analysis, privacy and security analysis and extensive testing is absolutely necessary to produce fair and explainable AI that would inspire trust and transparency, and produce confidence among executives that the system will operate within its boundaries. Lastly, incorporating human judgement and knowledge in this intricate process is crucial for organizations who want to move forward with AI with greater trust and confidence.
References:
[1] Say hi to your new boss: How algorithms might soon control our lives. - Discrimination and ethics in the data-driven society (https://media.ccc.de/v/32c3-7482-say_hi_to_your_new_boss_how_algorithms_might_soon_control_our_lives)
[2] Machine Bias - https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[3] Minority Neighborhoods Pay Higher Car Insurance Premiums Than White Areas With the Same Risk - (https://www.propublica.org/article/minority-neighborhoods-higher-car-insurance-premiums-white-areas-same-risk)
[4] Blaise Aguera y Arcas, Margaret Mitchell, and Alexander Todorov, “Physiognomy’s New Clothes,”
Medium, May 7, 2017, https://medium.com/@blaisea/physiognomys-new-clothes-f2d4b59fdd6a .
[5] Parliament and Council of the European Union (2016). General Data Protection Regulation.
[6] Young, P., Lai, A., Hodosh, M., and Hockenmaier, J.(2014). From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. TACL, 2:67–78.
[7] Stereotyping and Bias in the Flickr30K Dataset (https://arxiv.org/pdf/1605.06083.pdf)
[8] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla,
M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015
[9] No Classification without Representation:Assessing Geodiversity Issues in Open Data Sets for the Developing World - (https://arxiv.org/abs/1711.08536)
[10] Predictive Inequity in Object Detection - (https://arxiv.org/pdf/1902.11097.pdf)
[11] Semantics derived automatically from language corpora contain human-like biases - (https://www.researchgate.net/publication/316973825_Semantics_derived_automatically_from_language_corpora_contain_human-like_biases)
[12] Datasheets for Datasets – (https://arxiv.org/pdf/1803.09010.pdf)
[13] Evaluating Fairness Metrics in the Presence of Dataset Bias - (https://arxiv.org/pdf/1809.09245.pdf)
[14] Amazon Doesn’t Consider the Race of Its Customers. Should It?
- https://www.bloomberg.com/graphics/2016-amazon-same-day/index.html
[15] Dwork C, Roth A. The algorithmic foundations of differential privacy. Found Trends Theor Comput Sci. 2014;9(3– 4):211–407. https://doi.org/10.1561/0400000042.
[16] I'd blush if I could: closing gender divides in digital skills through education - https://unesdoc.unesco.org/ark:/48223/pf0000367416.page=1
[17] Inherent Trade-Offs in the Fair Determination of Risk Scores - (https://arxiv.org/abs/1609.05807)
[18] Equality of Opportunity in Supervised Learning - (https://arxiv.org/pdf/1610.02413.pdf)
[19] Delayed Impact of Fair Machine Learning (https://arxiv.org/pdf/1803.04383.pdf)
[20] Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Why should I trust you?: Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM (2016)
[21]A Unified Approach to Interpreting Model Predictions (http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions.pdf)
[22] Consistent feature attribution for tree ensembles - (https://arxiv.org/abs/1706.06060)
[23] Please Stop Explaining Black Box Models for High-Stakes Decisions –(https://arxiv.org/pdf/1811.10154.pdf)

















