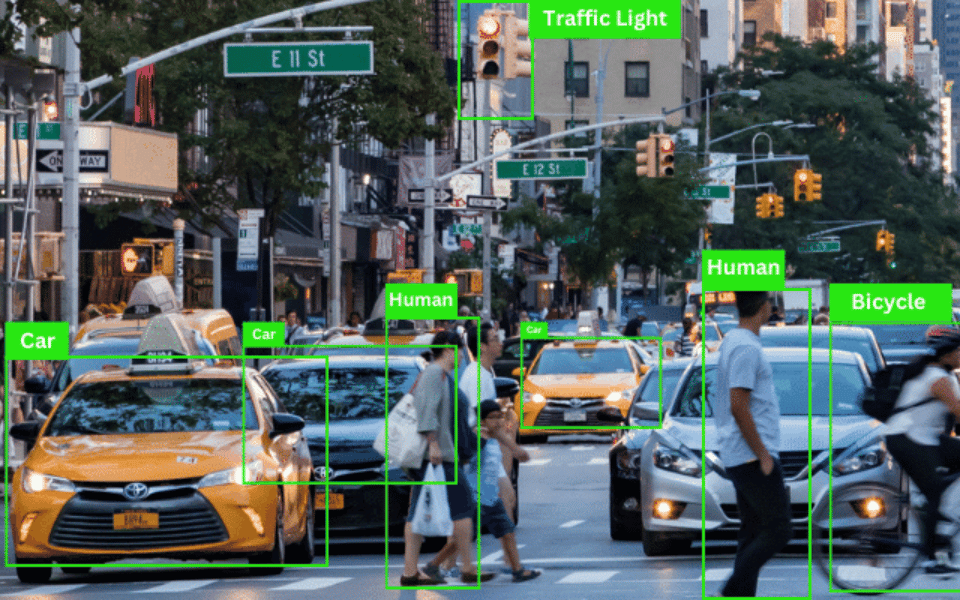
The Mars Climate Orbiter: In 1999, the Mars Climate Orbiter failed to enter its intended orbit around Mars and was destroyed upon entering the Martian atmosphere. The failure was caused by a software error that used the wrong units of measurement.
The Therac-25 radiation therapy machine: In the 1980s, the Therac-25 radiation therapy machine was responsible for the deaths of six people and severe injuries to hundreds more. The machine was flawed because it could deliver fatal doses of radiation due to software errors.
Yes, it is scary but in 2023, we have come a long way in building better software products.
In the ever-evolving landscape of software innovation and development, ensuring the reliability of software ecosystems is paramount. Designing for reliability involves integrating reliability engineering and quality engineering principles throughout the Software Development/ Quality Engineering Life Cycle (SDLC/QELC). By “left-shifting” these practices—incorporating them early in the development process—we can proactively address potential design, functional, and non-functional issues, reduce the likelihood of failures, and ultimately deliver more robust and dependable software.
The growing impact of Technical Debt (TD) has become the biggest obstacle to making any changes to existing code bases. TD principle increased to ~$1.52 trillion (because deficiencies are not getting fixed). CISQ | The Cost of Poor Software Quality in the US: A 2022 Report. Let’s explore how we can reduce it.
1. Requirements Phase: Setting the Foundation for Reliability
In the Requirements Phase, the foundation for a reliable software system needs to be laid down. This phase involves more than just listing product/app features and functionalities; it’s about clearly defining the expectations for how the software should perform and handle potential challenges. Let’s break down a few aspects with examples:
- Clearly define reliability requirements: Specify the expected level of performance, availability, and fault tolerance. Create a Requirement Traceability Matrix that becomes the single source of truth for all stakeholders.
Example: Imagine developing an online banking application. In this phase, specify that the system must be available 99.99% of the time to ensure customers can access their accounts reliably. Additionally, set a performance requirement, stating that transactions should be processed within one second to provide a seamless user experience. It is imperative to establish and comply with tolerances at various levels, including components, applications, services, and specific journey thresholds, all contributing to accurately formulating Error Budgets.
- Collaborate with stakeholders: Understand their expectations regarding the software’s reliability and incorporate these expectations into the project scope.
Example: Work closely with stakeholders, including bank executives, customer service representatives, and end-users. If customer service expects real-time transaction updates, this becomes a reliability expectation. By collaborating, ensure that the software aligns with the diverse needs and expectations of different stakeholders, creating a comprehensive reliability profile.
- Identify potential risks and establish mitigation plans: Identify potential risks related to reliability and establish mitigation plans early in the project.
Example: Consider the risk of third-party payment gateway failures in the banking application. During this phase, identify this as a potential reliability risk. To mitigate this, plan for an alternative payment gateway or implement a failover mechanism to switch to another provider in case of an outage seamlessly. This proactive approach minimizes the impact of potential failures.
By weaving these constructs into the Requirements Phase, the development team not only establishes a clear roadmap for reliability but also ensures that stakeholder expectations are aligned, and potential risks are mitigated before the first line of code is written. This proactive approach sets the tone for a development process prioritizing reliability from the beginning.
2. Design Phase: Building a Reliable Architecture
As the design phase unfolds, the focus shifts to constructing a resilient and dependable architecture that forms the backbone of reliable software. This is critical for enterprises – de novo or born-digital organizations need to know how fast and to what extent they can scale, and traditional enterprises need to understand how their legacy ecosystem will seamlessly interact with their new-age-front-end apps and API/microservices-based integrations.
- Implement Design for Reliability (DfR) Principles: Suppose you are developing a web-based project management application. Implement DfR principles by structuring the architecture to concurrent user interactions efficiently. This could involve using microservices to isolate functionalities, reducing the impact of a failure in one component on the entire system.
- Conduct Failure Mode and Effects Analysis (FMEA): In developing healthcare information system, conducting FMEA would involve identifying potential failure points. For instance, if the system is responsible for storing and retrieving patient data, analyze failure modes such as data corruption or loss. Design features, such as regular automated backups and data validation checks, to prevent or mitigate these failures.
- Integrate Redundancy and Error-Checking Mechanisms: Imagine developing a financial trading platform. Integrate redundancy by deploying the system across geographically distributed servers. Implement error-checking mechanisms that verify the accuracy of financial transactions, ensuring that trades are executed reliably, and errors are detected and corrected in real-time.
- Consider Scalability and Performance Requirements: Example: For an e-commerce platform, scalability is a critical factor. Design the architecture to handle varying loads during peak shopping seasons. This might involve implementing load-balancing techniques, optimizing database queries, and utilizing scalable cloud infrastructure to ensure the system remains reliable even when experiencing high user traffic.
The Design Phase needs to be thought through with these scenarios. This ensures that the software architecture is robust and built to withstand potential challenges. By proactively addressing failure points, implementing redundancy, and considering scalability requirements, the development team lays the groundwork for a system that functions reliably and adapts to the evolving demands of users and the environment.
3. Coding Phase: Writing Reliable Code:
At the heart of the development process, the Coding Phase is where the blueprint comes to life. Ensuring reliability at this stage involves writing functional code and crafting it with longevity and dependability in mind.
- Adhere to Coding Standards and Best Practices: Consider a team developing a mobile banking application. Adhering to coding standards could involve using clear and consistent variable naming conventions and organizing code modularly. This promotes reliability by making the codebase more understandable and maintainable, reducing the likelihood of introducing errors during future updates.
- Implement Unit Tests Early in the Development Process: For an e-commerce website, implementing unit tests early could involve creating test cases for critical functions like order processing and payment handling. By identifying and rectifying defects at the code level, the development team ensures that these essential functionalities work reliably, preventing potential issues downstream.
- Leverage Static Code Analysis Tools: Imagine developing a cloud-based collaboration tool. Utilize static code analysis tools to scan the codebase for potential reliability issues and security vulnerabilities. These tools can identify issues such as memory leaks or insecure coding practices, allowing developers to address them before the software reaches the testing phase.
- Encourage Code Reviews and Pair Programming: In the development of a customer relationship management (CRM) system, regular code reviews and pair programming sessions can be instrumental. Having multiple sets of eyes on the code makes reliability considerations, such as error handling and data validation, more likely to be identified and addressed. This collaborative approach ensures that reliable knowledge is shared across the development team.
Incorporating these examples into the Coding Phase ensures that the codebase functions as intended and lays the groundwork for a reliable and maintainable software product. By emphasizing coding standards, early testing, static code analysis, and collaborative coding practices, developers contribute to creating a resilient foundation that withstands the challenges of real-world usage.
4. Testing Phase: Rigorous Validation for Reliability
As the software enters the Testing Phase, the focus shifts to comprehensive validation, ensuring that the code meets the real-world challenges it will encounter.
- Conduct Comprehensive Functional and Non-functional Testing: Consider a web-based project management tool. Functional testing ensures that features like task assignments and progress tracking work as intended. Non-functional testing includes performance testing to verify that the system performs well under expected loads and security testing to identify vulnerabilities that could compromise reliability.
- Develop Automated Test Suites: In developing a healthcare information system, automated test suites can continuously assess the reliability of critical functionalities such as patient record updates and data retrieval. Automation ensures that these tests can be run consistently and repeatedly, providing quick feedback to developers on the reliability of their code throughout the development process.
- Simulate Real-world Scenarios: For a logistics and shipping software solution, simulating real-world scenarios might involve testing how the system handles a sudden surge in package tracking requests or network latency. By validating the software’s behavior under various conditions, the development team can identify potential failure points and proactively address them before deployment.
- Collaborate with Quality Assurance Teams: Imagine developing a financial analytics platform. Collaboration with quality assurance teams involves integrating reliability metrics into the testing strategy. This might include tracking response times for critical financial calculations or monitoring system behavior during peak usage periods. By incorporating these metrics, the testing process becomes more aligned with the reliability goals of the software.
Integrating these examples into the Testing Phase ensures that the software undergoes a robust and thorough examination. From functional and non-functional testing to automated test suites and simulations of real-world scenarios, the goal is to identify and rectify potential reliability issues before the software reaches the end users. Collaboration with quality assurance teams further strengthens the focus on reliability, making it an integral part of the overall testing strategy.
5. Deployment Phase:
As the software transitions to deployment, the focus shifts to seamlessly integrating new features and functionalities into the live environment. Ensuring reliability at this stage is critical for a smooth user experience.
- Implement Continuous Integration and Continuous Deployment (CI/CD) Pipelines: Suppose you are deploying updates for an e-commerce platform. Implementing CI/CD pipelines ensures automated testing and deployment of changes, reducing the likelihood of human error and ensuring that only thoroughly tested and reliable code reaches the production environment. This accelerates the deployment process and minimizes the risk of introducing configuration errors that could impact reliability.
- Monitor Software in Real-Time During Deployment: In deploying a real-time communication application, monitor the software in real-time as new features are rolled out. Use monitoring tools to track system performance, error rates, and user interactions during the deployment window. This proactive monitoring allows the development team to identify and address issues promptly, minimizing any potential impact on users.
- Implement Feature Toggles: Consider a social media platform rolling out a new commenting system. Implementing feature toggles allows the development team to turn the new commenting feature on or off without deploying new code. In case of unexpected reliability issues or negative user feedback, the feature can be easily toggled off, providing a quick and reversible solution without a complete rollback of the entire deployment.
By incorporating these techniques into the Deployment Phase, the development team ensures the reliable rollout of new features and establishes mechanisms for quick response and recovery in case of unexpected challenges. Automation through CI/CD pipelines reduces deployment time and potential errors, real-time monitoring allows for immediate issue identification, and feature toggles provide a safety net for rapid adjustments, all contributing to a reliable and user-friendly deployment process.
6. Maintenance Phase: Proactive Reliability Management
Once the software is live, the focus shifts to maintaining its reliability over time. Proactive measures and continuous improvements ensure a consistently dependable user experience.
- Establish a Robust Monitoring and Logging System: In a financial transaction system, establish a monitoring and logging system to track real-time transaction processing, system response times, and error rates. This allows the development team to identify potential reliability issues as they occur, enabling quick responses to maintain a seamless financial transaction experience for users.
- Conduct Regular Maintenance Activities: Consider a healthcare management system. Regular maintenance involves applying security patches to protect patient data, updating dependencies to ensure compatibility with the latest technologies, and optimizing database queries to maintain system performance. Collectively, these activities contribute to the long-term reliability and security of healthcare software.
- Encourage a Culture of Continuous Improvement: For logistics and shipping applications, encourage a culture of continuous improvement by collecting and analyzing reliability metrics. Metrics may include tracking the accuracy of package delivery times and system uptime. Use these metrics to inform future development iterations, allowing the team to prioritize enhancements that address reliability concerns and elevate the overall user experience.
By integrating these practices into the Maintenance Phase, the development team ensures that the software remains reliable and evolves to meet changing demands and challenges. Establishing a robust monitoring system allows for real-time issue identification, regular maintenance activities uphold the software’s health, and a culture of continuous improvement ensures that the software adapts to the dynamic landscape of user needs and technological advancements.
In conclusion, integrating reliability engineering principles across every phase of the SDLC/QELC, software development teams can create more dependable, resilient, and high-performance applications. Left shifting reliability engineering reduces the risk of post-deployment failures and fosters a proactive and collaborative approach to building software that meets and exceeds user expectations for reliability. As technology advances, embracing these principles becomes increasingly critical for delivering software that stands the test of time.