Since 2020, the demand for virtual healthcare has grown a staggering 38 times. This unprecedented expansion, in turn presents both significant opportunities and challenges for healthcare majors worldwide.
While the rapid growth has enabled multi-channel access to a larger patient-base, it has also triggered the generation of massive volumes of sensitive health-related data – an abundant hunting ground for cyber threat actors. At the same time, dependence on legacy, disparate systems present integrability challenges, especially with the rise of telehealth applications and the internet of medical things (IoMT) adding to the data proliferation.
Centers for Medicare & Medicaid Services (CMS) and the Office of the National Coordinator for Health IT (ONC), in response to the evolving scenario, have introduced policies that mandate the removal of current siloed data systems. These policies represent an attempt to enable seamless data-powered communication between hospitals, physicians, payers, pharmaceutical companies, and medical device and equipment manufacturers – thereby facilitating better health outcomes across the board.
From the operations perspective, the new regulations have compelled IT teams in Health Care Organizations (HCOs) to establish interoperability as a functional software requirement. The focus is on seamless and complete bidirectional transfer of health care information, inclusive of patient information, between relevant and approved stakeholders.
To achieve such interoperability, healthcare systems today must be able to communicate over a common interface. However, with over 40 standard development organizations (SDOs) in the healthcare IT arena, the struggle to choose the right standardized format for data interoperability and storage is a pressing concern for HCOs. The rapid expansion of data volumes is therefore leading to mounting industry-wide apprehensions, prompting an increase in cloud adoption – a transition that further underscores the critical need for streamlined data sharing as per the standard interoperable guidelines.
The Move toward Cloud-based Health Data Storage
A survey paper , published in April 2021, reported how HCOs were storing their patient information. The numbers revealed that while most HCOs were centralizing data, only about 24 percent of them were considering futureproofing themselves by configuring a sustainable hybrid cloud infrastructure.

Figure 1: Percentage of HCOs leveraging each storage solution
As Gartner puts it, even at this nascent stage, cloud-based healthcare data storage is emerging as a market disruptor. There is, however, some good news. Organizations are increasingly realizing the benefits of adopting a hybrid or multi cloud adoption approach to address potential cybersecurity issues. In 2022, only about three percent of organizations were using a single private or public cloud, far lower compared to the 29% high reached in 2019.
And HCOs shifting from traditional monolithic architecture and adopting a decentralized, shareable, and scalable cloud architecture are reaping the benefits too. One key advantage is the independence it grants from rigid IT infrastructures that restrict interoperability between servers. A second benefit is flexibility: the freedom to use hybrid/multi-cloud architecture on-demand to scale healthcare systems and deploy any number of cloud solutions as required.
Going forward, advancements in cloud innovations , including, intelligent cloud integration, cloud-enabled home automation, and autonomous multi-cloud container platforms, offer HCOs the promise of higher value, security, and connectivity capabilities.
However, this scenario is only possible when all functions have access to insights from uniformly categorized data.
FHIR and openEHR: Health Data Standards for Interoperability
IEEE formally defines interoperability as “the ability of two or more systems or components to exchange information and to use the information that has been exchanged.” This definition opens two conceptual levels,
Syntactical interoperability is the standardization of the data formats and communication which provides the fundamental linkage and integration between systems or their components. Here, one leverages the information models for inter-connecting heterogeneous data sources by using common forms/standards for cross -mapping.
Semantic interoperability addresses the challenges of accurately interpreting and utilizing the information exchanged through syntactic interoperability. Here, it focus on ways to tackle the challenges around user understandable, computable and extensible knowledge representation schemes.
Mapping the digital architecture requires an interoperability standard with uniform storage and access format. HCOs predominantly rely on Health Level 7’s (HL7) Fast Healthcare Interoperability Resources (FHIR) standard, which supports bidirectional data exchange for both data reading and entry. FHIR also enables more granular data types and documents and can be used for plug-and-play apps.
Healthcare APIs, such as Google Healthcare API , leverage FHIR to map and transfer data. In one example, the API enabled a large pharmacy to execute deeper patient engagement while reducing operational costs.
For a while now, FHIR has been the go-to standard for enabling semantic interoperability, where the system uses a common transport method to move data. However, ‘true’ data interoperability necessitates semantic interoperability as well, which helps the system leverage electronic health records (EHR) to understand the exact meaning and context of the data.
Over the years, however, with several versions of HL7, FHIR has failed to maintain semantic interoperability across the versions.
To stop the loss of data in translation, a consortium of HCOs introduced a new technology, driven by a domain-driven information systems platform with clinical models and specifications. openEHR helped created a bridge between domain professionals and IT developers, establishing a fixed meaning for each data type. The e-health technology enabled rapid application development through low-code tools, and at the same time, its pre-configured component-oriented interfaces helped deploy cost-effective interoperability.
To understand this better, FHIR’s primary objective centers around the creation of a system-to-system (B2B) and a system-to-application (B2C) nexus. The B2B part is essentially an information-based approach while the B2C part fulfils basic needs for facilitating state-of-the-art health system applications.
FHIR has more API coverage and is a cutting-edge project that has done an excellent job of creating APIs for complex tasks.
On the other hand, openEHR offers extensive coverage of patient citizen information, and significant coverage of the clinical model domain. It, however, has limited API compatibility.
The main goal of openEHR is to address the challenges around durable and computable records within an open source patient management system. This represents a long-term and forward-looking challenge, and, in turn, is addressed by leveraging platform architecture principles. What we must remember here is that openEHR itself only offers some elements of this platform, which itself must have access to suitable terminology, drug databases, and relevant service interfaces.
Interoperability Challenges for Cloud Adopters
While most HCOs recognize and use FHIR, openEHR is gaining attention for its robustness and adaptability. Through my interactions with industry professionals, We found a general confusion between the usage of FHIR and EHR. And to explain their usage, it’s best to put them into a cloud adoption perspective. Following are certain FHIR challenges that openEHR can address for HCOs looking to scale up or migrate to cloud environments.
The first challenge is the robustness of the data model. FHIR can model and store data for certain use cases. However, when the data volumes constitute broad and complex categories, openEHR is a more preferred standard. For instance, in the event of storing observation data for patients, FHIR can provide a few generic resources. openEHR, on the other hand, has a pre-designed template to observe a certain condition based on several parameters, including body temperature, blood pressure, and heart rate.
The second challenge is business intelligence and analytics. FHIR has a default set of REST APIs that IT developers use to explore datasets. This approach to querying data requires direct communication with the API that needs an understanding of the complex SQL dialects. openEHR’s AQL, the native query language, provides an interface for exploring data instead. However, this may not work for all analytics use cases that require operating on that data in various ways.
The third challenge, as briefly mentioned earlier, is versioning. New versions of HL7 standards have altered the semantics of modeled data. For example, the AllergyIntolerance resource has changed “assertedData” to “recordedDate”, which is semantically different from the earlier model. This poses a major issue when it comes to modeling data in the FHIR format. To address the challenge, developers have to either introduce a translation layer or migrate the entire data to the new version. In openEHR, the data model design embraces change through a base reference model. It has a set of generic base classes and types. This allows the platform to model clinical archetypes and templates for use in different use cases. Healthcare IT system developers can select their required parameters from the archetypes and templates to create their reference model, creating the modeling environment within the software.
Optimizing Interoperability in the Cloud with FHIR and openEHR
The above discussion leads us to a key realization – that both FHIR and openEHR play a critical role in ensuring effective interoperability within cloud environments. A forward-looking digital architecture on the cloud will need to be mapped with both FHIR and openEHR (Figure 2) for significant improvement in productivity, usability, and flexibility. FHIR and openEHR can be mapped according to specific use cases and requirements.
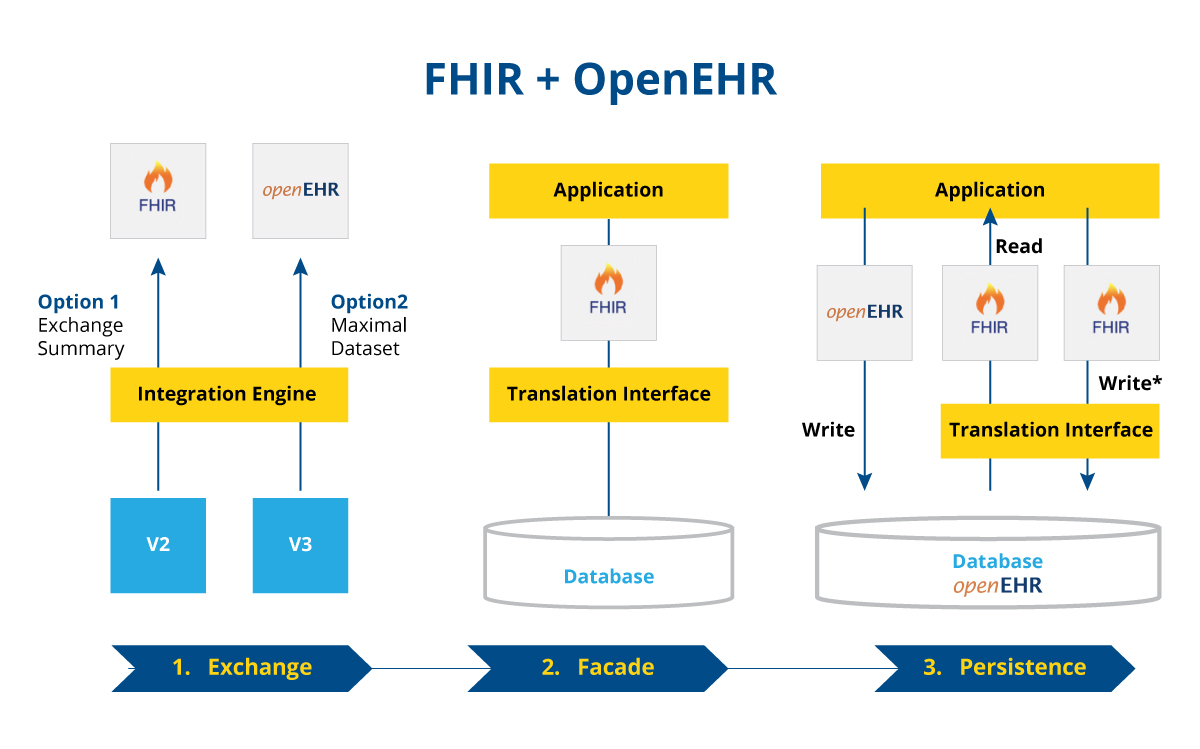
Figure 2: Basic digital architecture illustrating combined use of FHIR and openEHR
The first image illustrates a basic interoperable system for sharing summary information between applications. Here, FHIR helps connect the application systems while openEHR enables better control over the complex datasets.
The second image shows how developers can use openEHR as the translation interface for the FHIR API.
The third image depicts a more in-depth usage of openEHR, this time as an API. In some use cases, the openEHR API is used in conjunction with FHIR API to capture complex datasets and enable widespread interoperability.
The Future of Healthcare Data in MedTech:
Deploying both FHIR and openEHR in the cloud architecture provides the following key benefits:
- The combination of openEHR and FHIR enables health IT teams to ensure data in the cloud stays intact even after updates of HL7 standards.
- The combined interoperability helps IT teams scale using different cloud solutions without fear of losing data or losing their meaning.
- Standards set forth by EHR and FHIR allow healthcare companies to use opportunities provided by the cloud, such as remote communication with patients and physicians.
The realization of these benefits depends on the size of the health records, healthcare organizations, number of patients, and related factors.
What we must remember here is that the healthcare industry is now at a stage where integrating mature and complementary technologies could transform how we perceive patient outcomes and population health. With cloud computing improving scalability and agility for the companies, robust standards for interoperability and storage have become crucial for data usage and retention.

























